 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusedMM: A Unified SDDMM-SpMM Kernel for Graph Embedding and Graph Neural Networks
Nov 07, 2020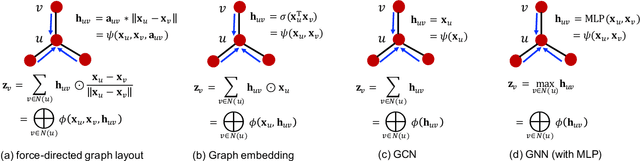
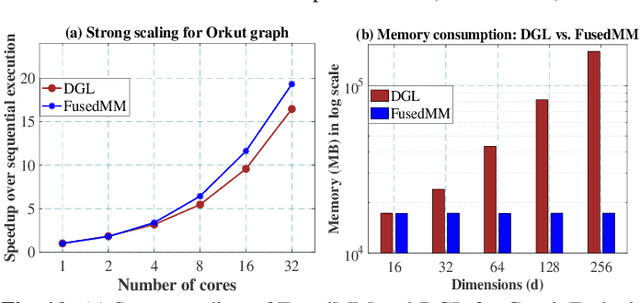
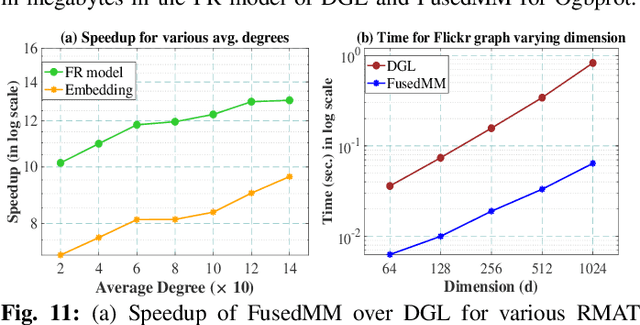
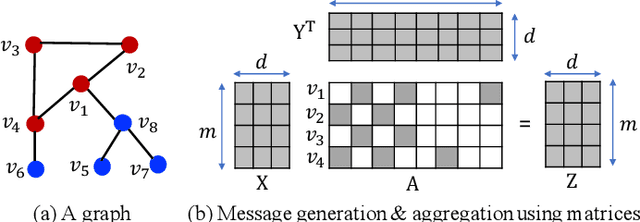
We develop a fused matrix multiplication kernel that unifies sampled dense-dense matrix multiplication and sparse-dense matrix multiplication under a single operation called FusedMM. By using user-defined functions, FusedMM can capture almost all computational patterns needed by popular graph embedding and GNN approaches. FusedMM is an order of magnitude faster than its equivalent kernels in Deep Graph Library. The superior performance of FusedMM comes from the low-level vectorized kernels, a suitable load balancing scheme and an efficient utilization of the memory bandwidth. FusedMM can tune its performance using a code generator and perform equally well on Intel, AMD and ARM processors. FusedMM speeds up an end-to-end graph embedding algorithm by up to 28x on different processors.
Force2Vec: Parallel force-directed graph embedding
Sep 17, 2020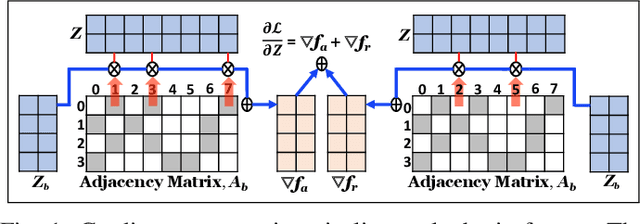
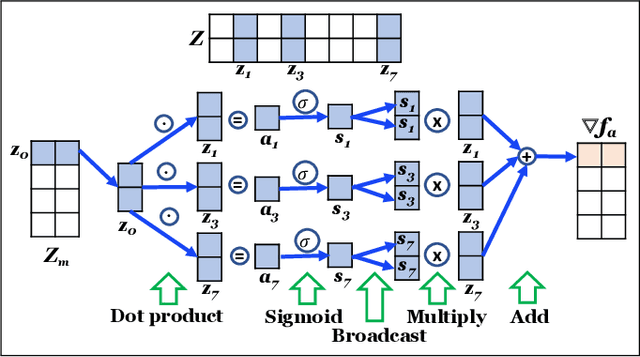
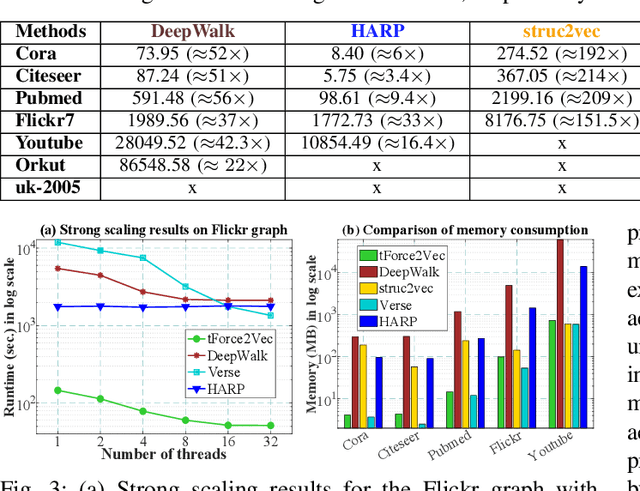

A graph embedding algorithm embeds a graph into a low-dimensional space such that the embedding preserves the inherent properties of the graph. While graph embedding is fundamentally related to graph visualization, prior work did not exploit this connection explicitly. We develop Force2Vec that uses force-directed graph layout models in a graph embedding setting with an aim to excel in both machine learning (ML) and visualization tasks. We make Force2Vec highly parallel by mapping its core computations to linear algebra and utilizing multiple levels of parallelism available in modern processors. The resultant algorithm is an order of magnitude faster than existing methods (43x faster than DeepWalk, on average) and can generate embeddings from graphs with billions of edges in a few hours. In comparison to existing methods, Force2Vec is better in graph visualization and performs comparably or better in ML tasks such as link prediction, node classification, and clustering. Source code is available at https://github.com/HipGraph/Force2Vec.