 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity Needs and Assets: A Computational Analysis of Community Conversations
Mar 20, 2024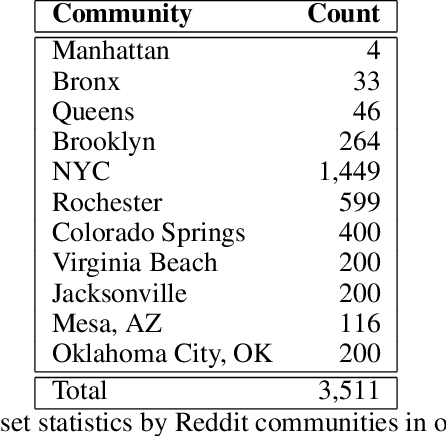
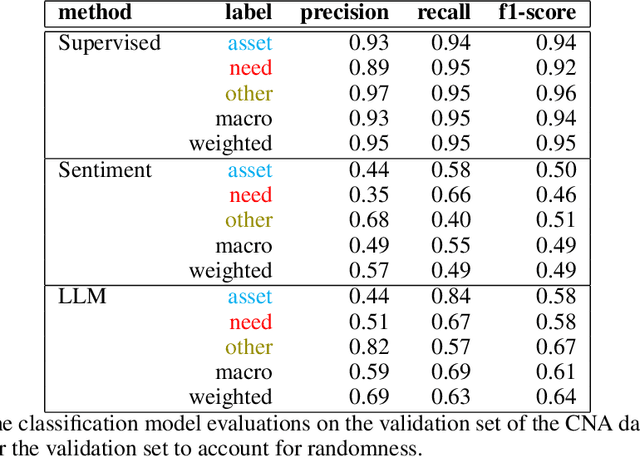

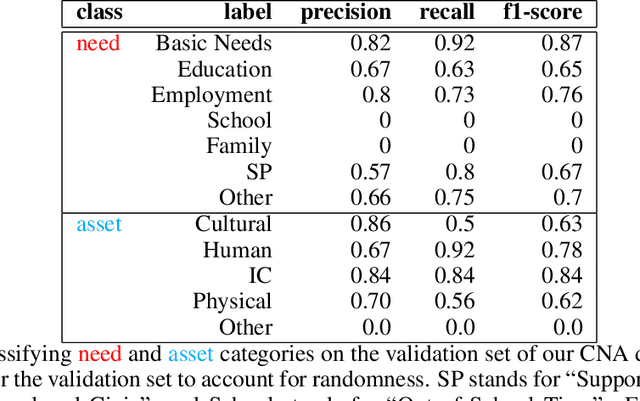
A community needs assessment is a tool used by non-profits and government agencies to quantify the strengths and issues of a community, allowing them to allocate their resources better. Such approaches are transitioning towards leveraging social media conversations to analyze the needs of communities and the assets already present within them. However, manual analysis of exponentially increasing social media conversations is challenging. There is a gap in the present literature in computationally analyzing how community members discuss the strengths and needs of the community. To address this gap, we introduce the task of identifying, extracting, and categorizing community needs and assets from conversational data using sophisticated natural language processing methods. To facilitate this task, we introduce the first dataset about community needs and assets consisting of 3,511 conversations from Reddit, annotated using crowdsourced workers. Using this dataset, we evaluate an utterance-level classification model compared to sentiment classification and a popular large language model (in a zero-shot setting), where we find that our model outperforms both baselines at an F1 score of 94% compared to 49% and 61% respectively. Furthermore, we observe through our study that conversations about needs have negative sentiments and emotions, while conversations about assets focus on location and entities. The dataset is available at https://github.com/towhidabsar/CommunityNeeds.
Infrastructure Ombudsman: Mining Future Failure Concerns from Structural Disaster Response
Feb 22, 2024Current research concentrates on studying discussions on social media related to structural failures to improve disaster response strategies. However, detecting social web posts discussing concerns about anticipatory failures is under-explored. If such concerns are channeled to the appropriate authorities, it can aid in the prevention and mitigation of potential infrastructural failures. In this paper, we develop an infrastructure ombudsman -- that automatically detects specific infrastructure concerns. Our work considers several recent structural failures in the US. We present a first-of-its-kind dataset of 2,662 social web instances for this novel task mined from Reddit and YouTube.
Community Learning: Understanding A Community Through NLP for Positive Impact
Oct 11, 2022A post-pandemic world resulted in economic upheaval, particularly for the cities' communities. While significant work in NLP4PI focuses on national and international events, there is a gap in bringing such state-of-the-art methods into the community development field. In order to help with community development, we must learn about the communities we develop. To that end, we propose the task of community learning as a computational task of extracting natural language data about the community, transforming and loading it into a suitable knowledge graph structure for further downstream applications. We study two particular cases of homelessness and education in showing the visualization capabilities of a knowledge graph, and also discuss other usefulness such a model can provide.