 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLemon and Orange Disease Classification using CNN-Extracted Features and Machine Learning Classifier
Aug 26, 2024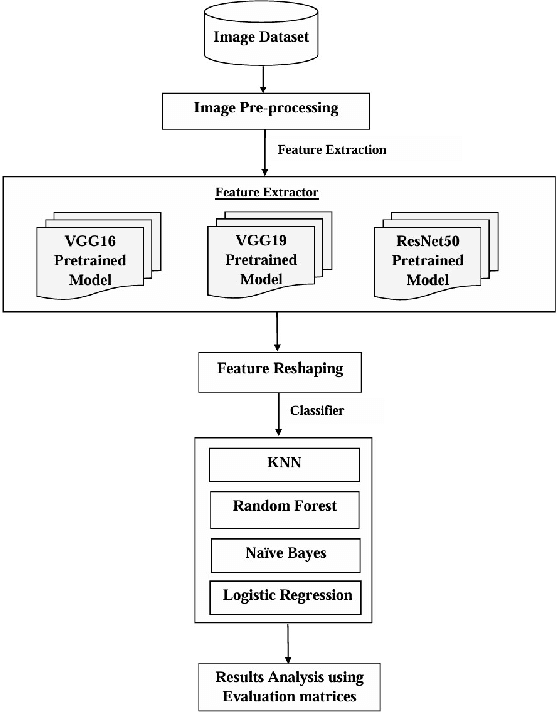


Lemons and oranges, both are the most economically significant citrus fruits globally. The production of lemons and oranges is severely affected due to diseases in its growth stages. Fruit quality has degraded due to the presence of flaws. Thus, it is necessary to diagnose the disease accurately so that we can avoid major loss of lemons and oranges. To improve citrus farming, we proposed a disease classification approach for lemons and oranges. This approach would enable early disease detection and intervention, reduce yield losses, and optimize resource allocation. For the initial modeling of disease classification, the research uses innovative deep learning architectures such as VGG16, VGG19 and ResNet50. In addition, for achieving better accuracy, the basic machine learning algorithms used for classification problems include Random Forest, Naive Bayes, K-Nearest Neighbors (KNN) and Logistic Regression. The lemon and orange fruits diseases are classified more accurately (95.0% for lemon and 99.69% for orange) by the model. The model's base features were extracted from the ResNet50 pre-trained model and the diseases are classified by the Logistic Regression which beats the performance given by VGG16 and VGG19 for other classifiers. Experimental outcomes show that the proposed model also outperforms existing models in which most of them classified the diseases using the Softmax classifier without using any individual classifiers.
Beyond Check-in Counts: Redefining Popularity for POI Recommendation with Users and Recency
Jul 07, 2024The next POI (point of interest) recommendation aims to predict users' immediate future movements based on their prior records and present circumstances, which will be very beneficial to service providers as well as users. The popularity of the POI over time is one of the primary deciding factors for choosing the next POI to visit. The majority of research in recent times has paid more attention to the number of check-ins to define the popularity of a point of interest, disregarding the temporal impact or number of people checking in for a particular POI. In this paper, we propose a recency-oriented definition of popularity that takes into account the temporal effect on POI's popularity, the number of check-ins, as well as the number of people who registered those check-ins. Thus, recent check-ins get prioritized with more weight compared to the older ones. Experimental results demonstrate that performance is better with recency-aware popularity definitions for POIs than with solely check-in count-based popularity definitions.
An Isolation Forest Learning Based Outlier Detection Approach for Effectively Classifying Cyber Anomalies
Dec 09, 2020Cybersecurity has recently gained considerable interest in today's security issues because of the popularity of the Internet-of-Things (IoT), the considerable growth of mobile networks, and many related apps. Therefore, detecting numerous cyber-attacks in a network and creating an effective intrusion detection system plays a vital role in today's security. In this paper, we present an Isolation Forest Learning-Based Outlier Detection Model for effectively classifying cyber anomalies. In order to evaluate the efficacy of the resulting Outlier Detection model, we also use several conventional machine learning approaches, such as Logistic Regression (LR), Support Vector Machine (SVM), AdaBoost Classifier (ABC), Naive Bayes (NB), and K-Nearest Neighbor (KNN). The effectiveness of our proposed Outlier Detection model is evaluated by conducting experiments on Network Intrusion Dataset with evaluation metrics such as precision, recall, F1-score, and accuracy. Experimental results show that the classification accuracy of cyber anomalies has been improved after removing outliers.