 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of the User Perception of Chatbots in Education Using A Partial Least Squares Structural Equation Modeling Approach
Nov 07, 2023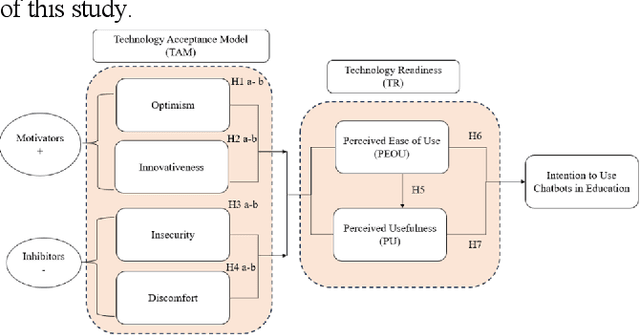
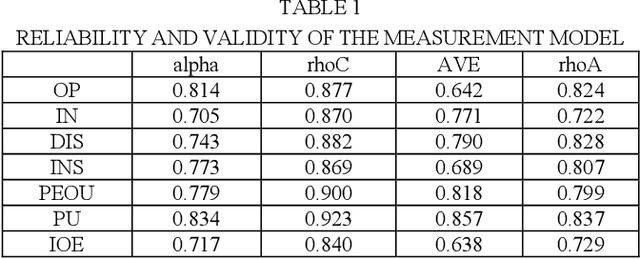

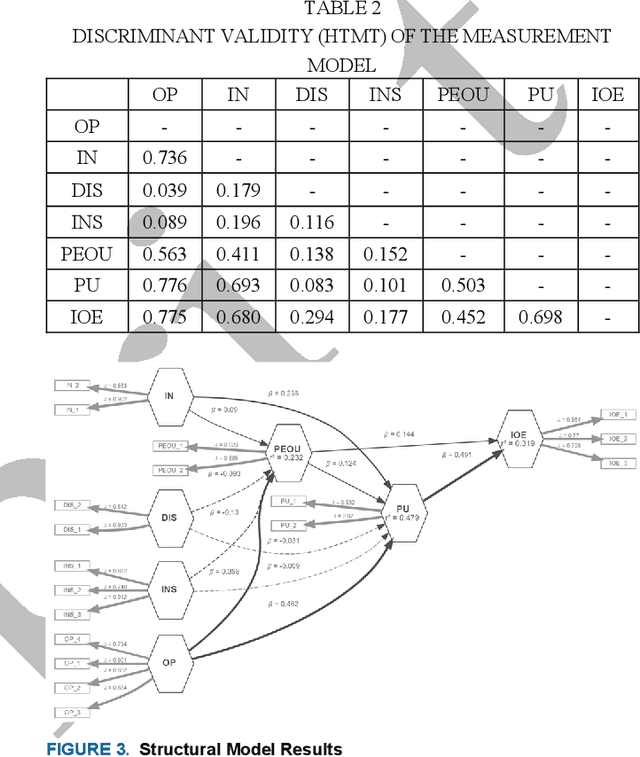
The integration of Artificial Intelligence (AI) into education is a recent development, with chatbots emerging as a noteworthy addition to this transformative landscape. As online learning platforms rapidly advance, students need to adapt swiftly to excel in this dynamic environment. Consequently, understanding the acceptance of chatbots, particularly those employing Large Language Model (LLM) such as Chat Generative Pretrained Transformer (ChatGPT), Google Bard, and other interactive AI technologies, is of paramount importance. However, existing research on chatbots in education has overlooked key behavior-related aspects, such as Optimism, Innovativeness, Discomfort, Insecurity, Transparency, Ethics, Interaction, Engagement, and Accuracy, creating a significant literature gap. To address this gap, this study employs Partial Least Squares Structural Equation Modeling (PLS-SEM) to investigate the determinant of chatbots adoption in education among students, considering the Technology Readiness Index (TRI) and Technology Acceptance Model (TAM). Utilizing a five-point Likert scale for data collection, we gathered a total of 185 responses, which were analyzed using R-Studio software. We established 12 hypotheses to achieve its objectives. The results showed that Optimism and Innovativeness are positively associated with Perceived Ease of Use (PEOU) and Perceived Usefulness (PU). Conversely, Discomfort and Insecurity negatively impact PEOU, with only Insecurity negatively affecting PU. These findings provide insights for future technology designers, elucidating critical user behavior factors influencing chatbots adoption and utilization in educational contexts.
Cardiovascular Disease Risk Prediction via Social Media
Sep 28, 2023Researchers use Twitter and sentiment analysis to predict Cardiovascular Disease (CVD) risk. We developed a new dictionary of CVD-related keywords by analyzing emotions expressed in tweets. Tweets from eighteen US states, including the Appalachian region, were collected. Using the VADER model for sentiment analysis, users were classified as potentially at CVD risk. Machine Learning (ML) models were employed to classify individuals' CVD risk and applied to a CDC dataset with demographic information to make the comparison. Performance evaluation metrics such as Test Accuracy, Precision, Recall, F1 score, Mathew's Correlation Coefficient (MCC), and Cohen's Kappa (CK) score were considered. Results demonstrated that analyzing tweets' emotions surpassed the predictive power of demographic data alone, enabling the identification of individuals at potential risk of developing CVD. This research highlights the potential of Natural Language Processing (NLP) and ML techniques in using tweets to identify individuals with CVD risks, providing an alternative approach to traditional demographic information for public health monitoring.
ML Algorithm Synthesizing Domain Knowledge for Fungal Spores Concentration Prediction
Sep 23, 2023



The pulp and paper manufacturing industry requires precise quality control to ensure pure, contaminant-free end products suitable for various applications. Fungal spore concentration is a crucial metric that affects paper usability, and current testing methods are labor-intensive with delayed results, hindering real-time control strategies. To address this, a machine learning algorithm utilizing time-series data and domain knowledge was proposed. The optimal model employed Ridge Regression achieving an MSE of 2.90 on training and validation data. This approach could lead to significant improvements in efficiency and sustainability by providing real-time predictions for fungal spore concentrations. This paper showcases a promising method for real-time fungal spore concentration prediction, enabling stringent quality control measures in the pulp-and-paper industry.
Multi model LSTM architecture for Track Association based on Automatic Identification System Data
Apr 04, 2023For decades, track association has been a challenging problem in marine surveillance, which involves the identification and association of vessel observations over time. However, the Automatic Identification System (AIS) has provided a new opportunity for researchers to tackle this problem by offering a large database of dynamic and geo-spatial information of marine vessels. With the availability of such large databases, researchers can now develop sophisticated models and algorithms that leverage the increased availability of data to address the track association challenge effectively. Furthermore, with the advent of deep learning, track association can now be approached as a data-intensive problem. In this study, we propose a Long Short-Term Memory (LSTM) based multi-model framework for track association. LSTM is a recurrent neural network architecture that is capable of processing multivariate temporal data collected over time in a sequential manner, enabling it to predict current vessel locations from historical observations. Based on these predictions, a geodesic distance based similarity metric is then utilized to associate the unclassified observations to their true tracks (vessels). We evaluate the performance of our approach using standard performance metrics, such as precision, recall, and F1 score, which provide a comprehensive summary of the accuracy of the proposed framework.
A CNN-LSTM Architecture for Marine Vessel Track Association Using Automatic Identification System Data
Mar 24, 2023In marine surveillance, distinguishing between normal and anomalous vessel movement patterns is critical for identifying potential threats in a timely manner. Once detected, it is important to monitor and track these vessels until a necessary intervention occurs. To achieve this, track association algorithms are used, which take sequential observations comprising geological and motion parameters of the vessels and associate them with respective vessels. The spatial and temporal variations inherent in these sequential observations make the association task challenging for traditional multi-object tracking algorithms. Additionally, the presence of overlapping tracks and missing data can further complicate the trajectory tracking process. To address these challenges, in this study, we approach this tracking task as a multivariate time series problem and introduce a 1D CNN-LSTM architecture-based framework for track association. This special neural network architecture can capture the spatial patterns as well as the long-term temporal relations that exist among the sequential observations. During the training process, it learns and builds the trajectory for each of these underlying vessels. Once trained, the proposed framework takes the marine vessel's location and motion data collected through the Automatic Identification System (AIS) as input and returns the most likely vessel track as output in real-time. To evaluate the performance of our approach, we utilize an AIS dataset containing observations from 327 vessels traveling in a specific geographic region. We measure the performance of our proposed framework using standard performance metrics such as accuracy, precision, recall, and F1 score. When compared with other competitive neural network architectures our approach demonstrates a superior tracking performance.