 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossVal: Efficient Data Valuation for Neural Networks
Dec 05, 2024Assessing the importance of individual training samples is a key challenge in machine learning. Traditional approaches retrain models with and without specific samples, which is computationally expensive and ignores dependencies between data points. We introduce LossVal, an efficient data valuation method that computes importance scores during neural network training by embedding a self-weighting mechanism into loss functions like cross-entropy and mean squared error. LossVal reduces computational costs, making it suitable for large datasets and practical applications. Experiments on classification and regression tasks across multiple datasets show that LossVal effectively identifies noisy samples and is able to distinguish helpful from harmful samples. We examine the gradient calculation of LossVal to highlight its advantages. The source code is available at: https://github.com/twibiral/LossVal
Pairwise Difference Learning for Classification
Jun 28, 2024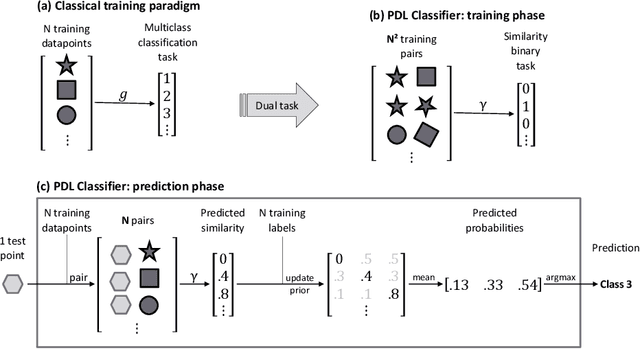

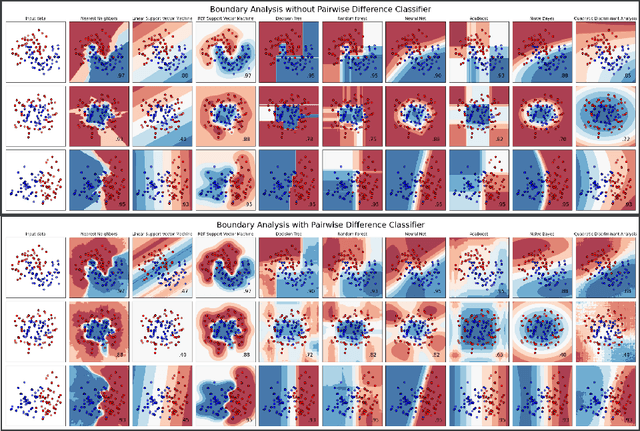

Pairwise difference learning (PDL) has recently been introduced as a new meta-learning technique for regression. Instead of learning a mapping from instances to outcomes in the standard way, the key idea is to learn a function that takes two instances as input and predicts the difference between the respective outcomes. Given a function of this kind, predictions for a query instance are derived from every training example and then averaged. This paper extends PDL toward the task of classification and proposes a meta-learning technique for inducing a PDL classifier by solving a suitably defined (binary) classification problem on a paired version of the original training data. We analyze the performance of the PDL classifier in a large-scale empirical study and find that it outperforms state-of-the-art methods in terms of prediction performance. Last but not least, we provide an easy-to-use and publicly available implementation of PDL in a Python package.
Optimizing Data Shapley Interaction Calculation from O(2^n) to O(t n^2) for KNN models
Apr 02, 2023



With the rapid growth of data availability and usage, quantifying the added value of each training data point has become a crucial process in the field of artificial intelligence. The Shapley values have been recognized as an effective method for data valuation, enabling efficient training set summarization, acquisition, and outlier removal. In this paper, we introduce "STI-KNN", an innovative algorithm that calculates the exact pair-interaction Shapley values for KNN models in O(t n^2) time, which is a significant improvement over the O(2^n)$ time complexity of baseline methods. By using STI-KNN, we can efficiently and accurately evaluate the value of individual data points, leading to improved training outcomes and ultimately enhancing the effectiveness of artificial intelligence applications.