 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight error mitigation strategies for post-training N:M activation sparsity in LLMs
Sep 26, 2025The demand for efficient large language model (LLM) inference has intensified the focus on sparsification techniques. While semi-structured (N:M) pruning is well-established for weights, its application to activation pruning remains underexplored despite its potential for dynamic, input-adaptive compression and reductions in I/O overhead. This work presents a comprehensive analysis of methods for post-training N:M activation pruning in LLMs. Across multiple LLMs, we demonstrate that pruning activations enables superior preservation of generative capabilities compared to weight pruning at equivalent sparsity levels. We evaluate lightweight, plug-and-play error mitigation techniques and pruning criteria, establishing strong hardware-friendly baselines that require minimal calibration. Furthermore, we explore sparsity patterns beyond NVIDIA's standard 2:4, showing that the 16:32 pattern achieves performance nearly on par with unstructured sparsity. However, considering the trade-off between flexibility and hardware implementation complexity, we focus on the 8:16 pattern as a superior candidate. Our findings provide both effective practical methods for activation pruning and a motivation for future hardware to support more flexible sparsity patterns. Our code is available https://anonymous.4open.science/r/Structured-Sparse-Activations-Inference-EC3C/README.md .
GIFT-SW: Gaussian noise Injected Fine-Tuning of Salient Weights for LLMs
Aug 27, 2024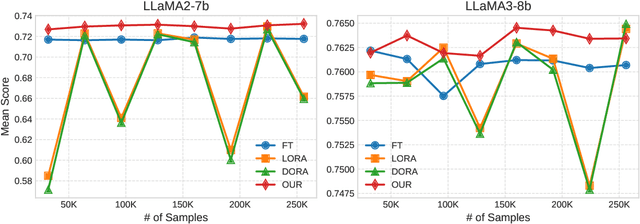
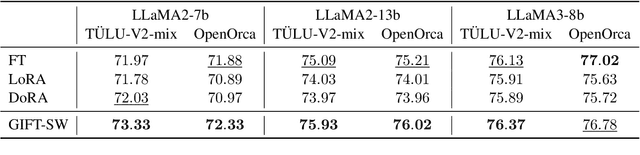
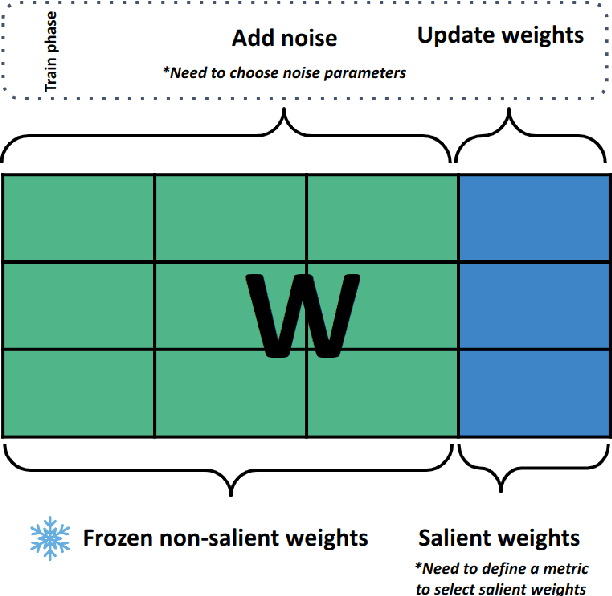
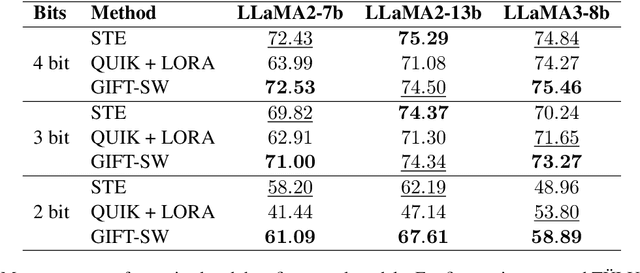
Parameter Efficient Fine-Tuning (PEFT) methods have gained popularity and democratized the usage of Large Language Models (LLMs). Recent studies have shown that a small subset of weights significantly impacts performance. Based on this observation, we introduce a novel PEFT method, called Gaussian noise Injected Fine Tuning of Salient Weights (GIFT-SW). Our method updates only salient columns, while injecting Gaussian noise into non-salient ones. To identify these columns, we developeda generalized sensitivity metric that extends and unifies metrics from previous studies. Experiments with LLaMA models demonstrate that GIFT-SW outperforms full fine-tuning and modern PEFT methods under the same computational budget. Moreover, GIFT-SW offers practical advantages to recover performance of models subjected to mixed-precision quantization with keeping salient weights in full precision.
Self-Supervised Learning in Event Sequences: A Comparative Study and Hybrid Approach of Generative Modeling and Contrastive Learning
Jan 30, 2024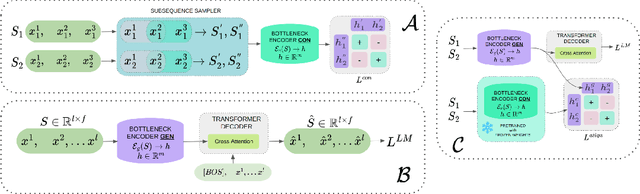

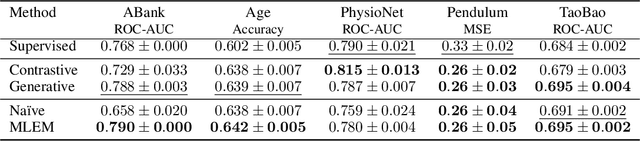

This study investigates self-supervised learning techniques to obtain representations of Event Sequences. It is a key modality in various applications, including but not limited to banking, e-commerce, and healthcare. We perform a comprehensive study of generative and contrastive approaches in self-supervised learning, applying them both independently. We find that there is no single supreme method. Consequently, we explore the potential benefits of combining these approaches. To achieve this goal, we introduce a novel method that aligns generative and contrastive embeddings as distinct modalities, drawing inspiration from contemporary multimodal research. Generative and contrastive approaches are often treated as mutually exclusive, leaving a gap for their combined exploration. Our results demonstrate that this aligned model performs at least on par with, and mostly surpasses, existing methods and is more universal across a variety of tasks. Furthermore, we demonstrate that self-supervised methods consistently outperform the supervised approach on our datasets.