 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning in Event Sequences: A Comparative Study and Hybrid Approach of Generative Modeling and Contrastive Learning
Paper and Code
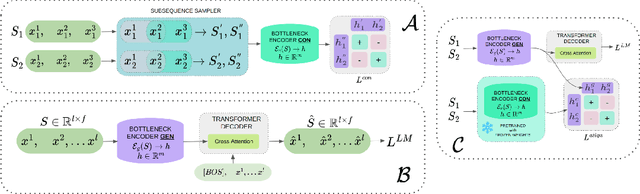

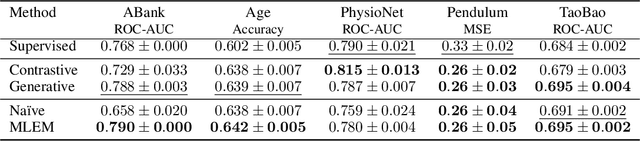

This study investigates self-supervised learning techniques to obtain representations of Event Sequences. It is a key modality in various applications, including but not limited to banking, e-commerce, and healthcare. We perform a comprehensive study of generative and contrastive approaches in self-supervised learning, applying them both independently. We find that there is no single supreme method. Consequently, we explore the potential benefits of combining these approaches. To achieve this goal, we introduce a novel method that aligns generative and contrastive embeddings as distinct modalities, drawing inspiration from contemporary multimodal research. Generative and contrastive approaches are often treated as mutually exclusive, leaving a gap for their combined exploration. Our results demonstrate that this aligned model performs at least on par with, and mostly surpasses, existing methods and is more universal across a variety of tasks. Furthermore, we demonstrate that self-supervised methods consistently outperform the supervised approach on our datasets.