 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAIPAT -Dataset on Human Gaze and Actions for Intent Prediction in Assembly Tasks
Mar 14, 2025



The primary objective of the dataset is to provide a better understanding of the coupling between human actions and gaze in a shared working environment with a cobot, with the aim of signifcantly enhancing the effciency and safety of humancobot interactions. More broadly, by linking gaze patterns with physical actions, the dataset offers valuable insights into cognitive processes and attention dynamics in the context of assembly tasks. The proposed dataset contains gaze and action data from approximately 80 participants, recorded during simulated industrial assembly tasks. The tasks were simulated using controlled scenarios in which participants manipulated educational building blocks. Gaze data was collected using two different eye-tracking setups -head-mounted and remote-while participants worked in two positions: sitting and standing.
TempAMLSI : Temporal Action Model Learning based on Grammar Induction
Dec 08, 2021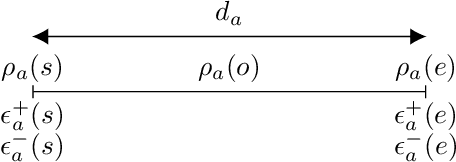
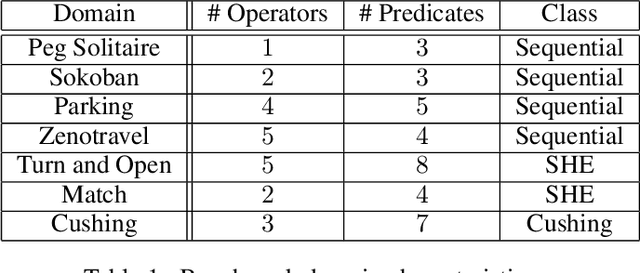
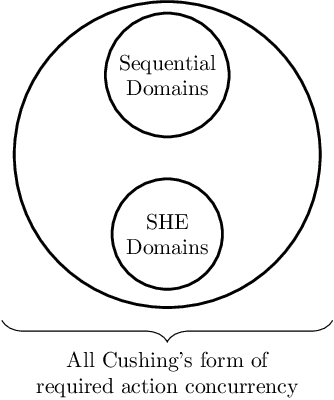
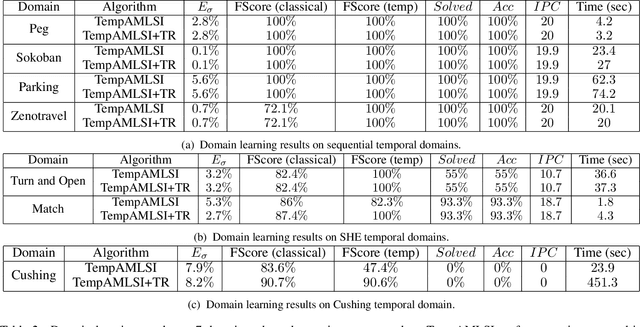
Hand-encoding PDDL domains is generally accepted as difficult, tedious and error-prone. The difficulty is even greater when temporal domains have to be encoded. Indeed, actions have a duration and their effects are not instantaneous. In this paper, we present TempAMLSI, an algorithm based on the AMLSI approach able to learn temporal domains. TempAMLSI is based on the classical assumption done in temporal planning that it is possible to convert a non-temporal domain into a temporal domain. TempAMLSI is the first approach able to learn temporal domain with single hard envelope and Cushing's intervals. We show experimentally that TempAMLSI is able to learn accurate temporal domains, i.e., temporal domain that can be used directly to solve new planning problem, with different forms of action concurrency.
AMLSI: A Novel Accurate Action Model Learning Algorithm
Nov 26, 2020
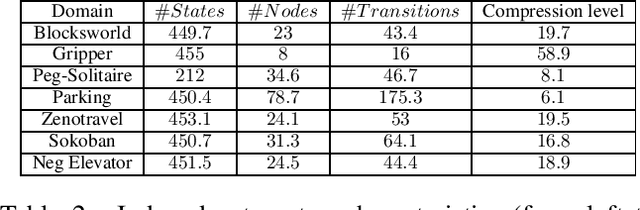
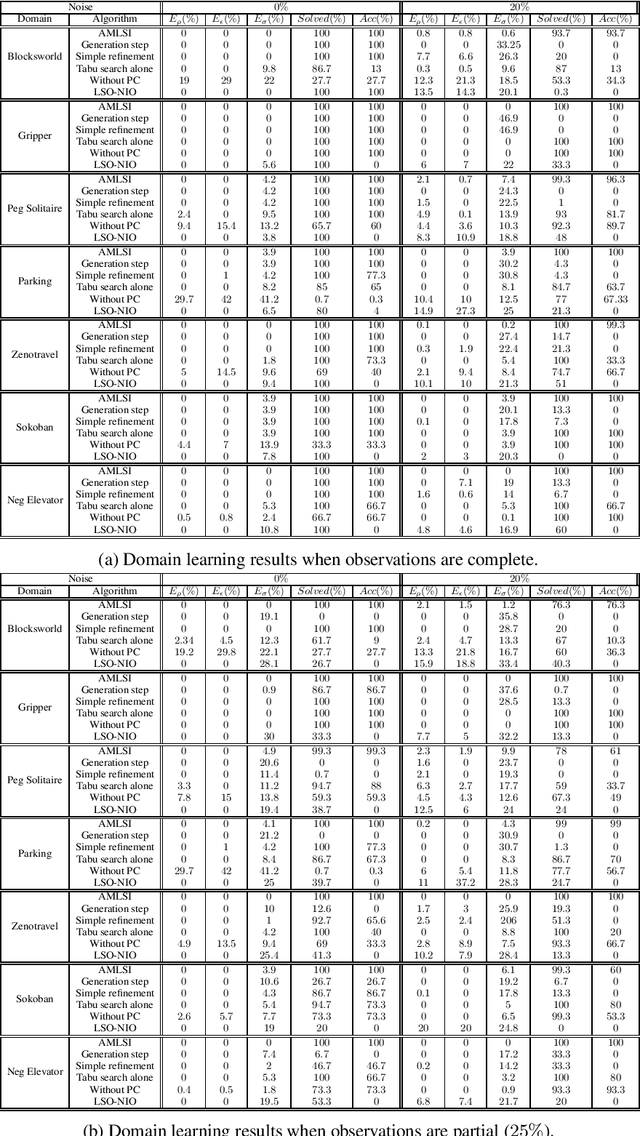
This paper presents new approach based on grammar induction called AMLSI Action Model Learning with State machine Interactions. The AMLSI approach does not require a training dataset of plan traces to work. AMLSI proceeds by trial and error: it queries the system to learn with randomly generated action sequences, and it observes the state transitions of the system, then AMLSI returns a PDDL domain corresponding to the system. A key issue for domain learning is the ability to plan with the learned domains. It often happens that a small learning error leads to a domain that is unusable for planning. Unlike other algorithms, we show that AMLSI is able to lift this lock by learning domains from partial and noisy observations with sufficient accuracy to allow planners to solve new problems.
* 8 pages