 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMLSI: A Novel Accurate Action Model Learning Algorithm
Paper and Code
Nov 26, 2020
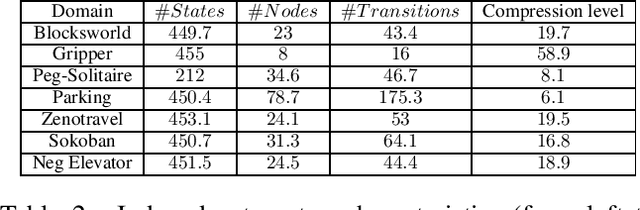
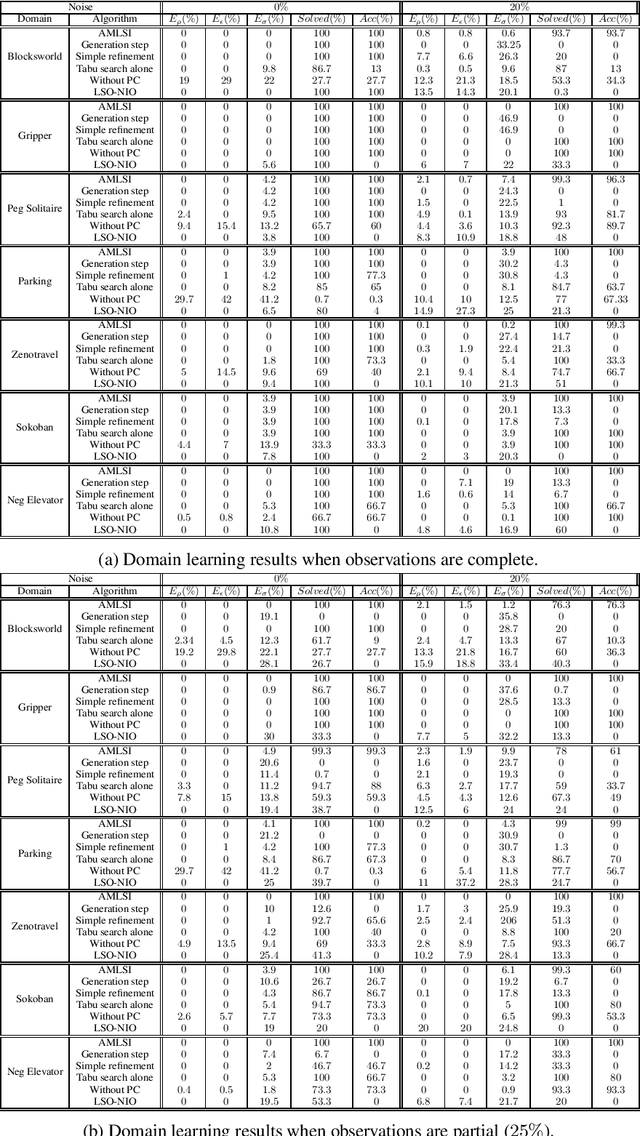
This paper presents new approach based on grammar induction called AMLSI Action Model Learning with State machine Interactions. The AMLSI approach does not require a training dataset of plan traces to work. AMLSI proceeds by trial and error: it queries the system to learn with randomly generated action sequences, and it observes the state transitions of the system, then AMLSI returns a PDDL domain corresponding to the system. A key issue for domain learning is the ability to plan with the learned domains. It often happens that a small learning error leads to a domain that is unusable for planning. Unlike other algorithms, we show that AMLSI is able to lift this lock by learning domains from partial and noisy observations with sufficient accuracy to allow planners to solve new problems.