 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement learning for online hyperparameter tuning in convex quadratic programming
Sep 09, 2025Quadratic programming is a workhorse of modern nonlinear optimization, control, and data science. Although regularized methods offer convergence guarantees under minimal assumptions on the problem data, they can exhibit the slow tail-convergence typical of first-order schemes, thus requiring many iterations to achieve high-accuracy solutions. Moreover, hyperparameter tuning significantly impacts on the solver performance but how to find an appropriate parameter configuration remains an elusive research question. To address these issues, we explore how data-driven approaches can accelerate the solution process. Aiming at high-accuracy solutions, we focus on a stabilized interior-point solver and carefully handle its two-loop flow and control parameters. We will show that reinforcement learning can make a significant contribution to facilitating the solver tuning and to speeding up the optimization process. Numerical experiments demonstrate that, after a lightweight training, the learned policy generalizes well to different problem classes with varying dimensions and to various solver configurations.
Path planning for autonomous vehicles with minimal collision severity
Aug 28, 2024



This paper proposes a path planning algorithm for autonomous vehicles, evaluating collision severity with respect to both static and dynamic obstacles. A collision severity map is generated from ratings, quantifying the severity of collisions. A two-level optimal control problem is designed. At the first level, the objective is to identify paths with the lowest collision severity. Subsequently, at the second level, among the paths with lowest collision severity, the one requiring the minimum steering effort is determined. Finally, numerical simulations were conducted using the optimal control software OCPID-DAE1. The study focuses on scenarios where collisions are unavoidable. Results demonstrate the effectiveness and significance of this approach in finding a path with minimum collision severity for autonomous vehicles. Furthermore, this paper illustrates how the ratings for collision severity influence the behaviour of the automated vehicle.
Collision Avoidance using Iterative Dynamic and Nonlinear Programming with Adaptive Grid Refinements
Nov 12, 2023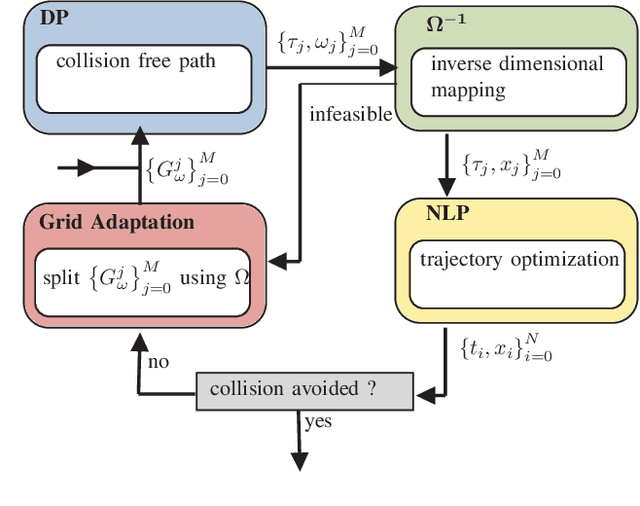
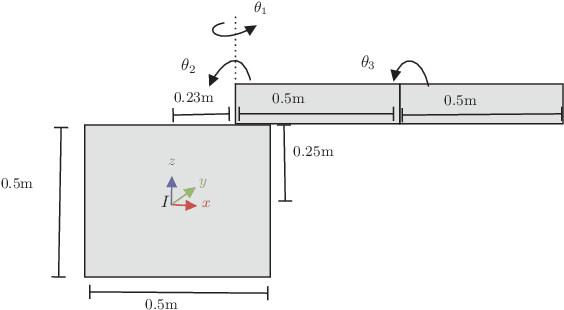
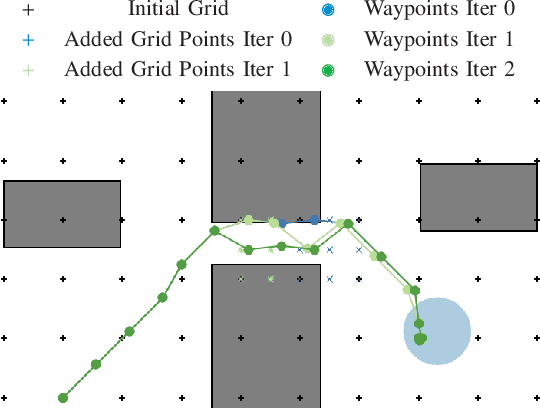
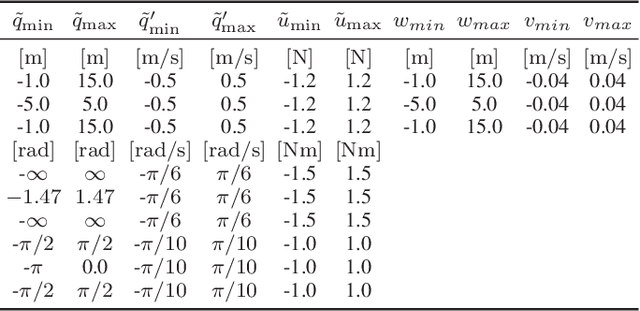
Nonlinear optimal control problems for trajectory planning with obstacle avoidance present several challenges. While general-purpose optimizers and dynamic programming methods struggle when adopted separately, their combination enabled by a penalty approach was found capable of handling highly nonlinear systems while overcoming the curse of dimensionality. Nevertheless, using dynamic programming with a fixed state space discretization limits the set of reachable solutions, hindering convergence or requiring enormous memory resources for uniformly spaced grids. In this work we solve this issue by incorporating an adaptive refinement of the state space grid, splitting cells where needed to better capture the problem structure while requiring less discretization points overall. Numerical results on a space manipulator demonstrate the improved robustness and efficiency of the combined method with respect to the single components.