 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollision Avoidance using Iterative Dynamic and Nonlinear Programming with Adaptive Grid Refinements
Paper and Code
Nov 12, 2023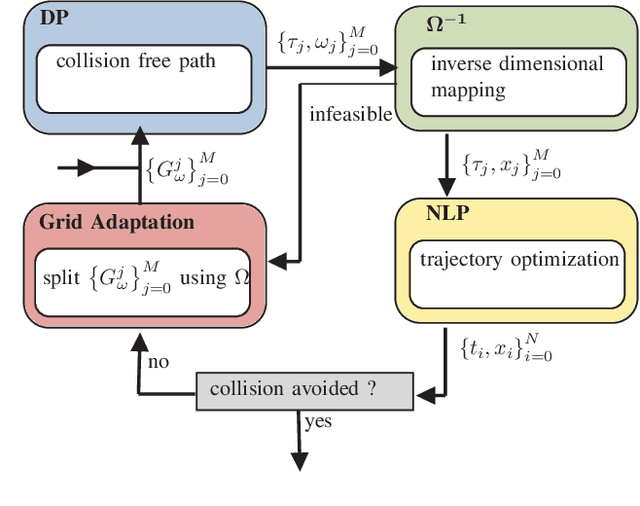
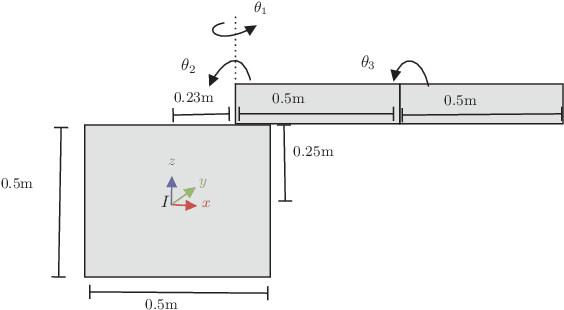
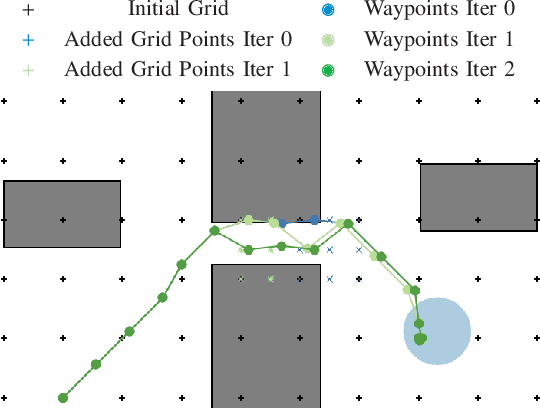
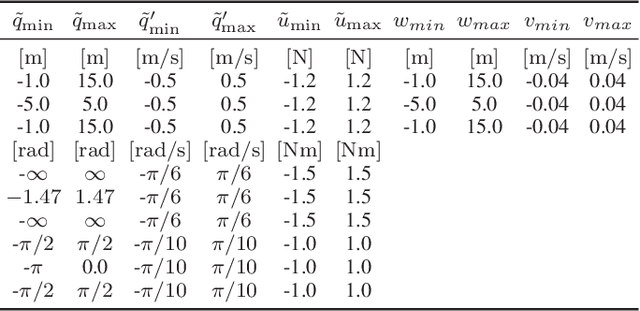
Nonlinear optimal control problems for trajectory planning with obstacle avoidance present several challenges. While general-purpose optimizers and dynamic programming methods struggle when adopted separately, their combination enabled by a penalty approach was found capable of handling highly nonlinear systems while overcoming the curse of dimensionality. Nevertheless, using dynamic programming with a fixed state space discretization limits the set of reachable solutions, hindering convergence or requiring enormous memory resources for uniformly spaced grids. In this work we solve this issue by incorporating an adaptive refinement of the state space grid, splitting cells where needed to better capture the problem structure while requiring less discretization points overall. Numerical results on a space manipulator demonstrate the improved robustness and efficiency of the combined method with respect to the single components.