 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Object Detection with Privileged Information: A Model-Agnostic Teacher-Student Approach
Jan 05, 2026This paper investigates the integration of the Learning Using Privileged Information (LUPI) paradigm in object detection to exploit fine-grained, descriptive information available during training but not at inference. We introduce a general, model-agnostic methodology for injecting privileged information-such as bounding box masks, saliency maps, and depth cues-into deep learning-based object detectors through a teacher-student architecture. Experiments are conducted across five state-of-the-art object detection models and multiple public benchmarks, including UAV-based litter detection datasets and Pascal VOC 2012, to assess the impact on accuracy, generalization, and computational efficiency. Our results demonstrate that LUPI-trained students consistently outperform their baseline counterparts, achieving significant boosts in detection accuracy with no increase in inference complexity or model size. Performance improvements are especially marked for medium and large objects, while ablation studies reveal that intermediate weighting of teacher guidance optimally balances learning from privileged and standard inputs. The findings affirm that the LUPI framework provides an effective and practical strategy for advancing object detection systems in both resource-constrained and real-world settings.
Correlation of Object Detection Performance with Visual Saliency and Depth Estimation
Nov 05, 2024As object detection techniques continue to evolve, understanding their relationships with complementary visual tasks becomes crucial for optimising model architectures and computational resources. This paper investigates the correlations between object detection accuracy and two fundamental visual tasks: depth prediction and visual saliency prediction. Through comprehensive experiments using state-of-the-art models (DeepGaze IIE, Depth Anything, DPT-Large, and Itti's model) on COCO and Pascal VOC datasets, we find that visual saliency shows consistently stronger correlations with object detection accuracy (mA$\rho$ up to 0.459 on Pascal VOC) compared to depth prediction (mA$\rho$ up to 0.283). Our analysis reveals significant variations in these correlations across object categories, with larger objects showing correlation values up to three times higher than smaller objects. These findings suggest incorporating visual saliency features into object detection architectures could be more beneficial than depth information, particularly for specific object categories. The observed category-specific variations also provide insights for targeted feature engineering and dataset design improvements, potentially leading to more efficient and accurate object detection systems.
Integrating Saliency Ranking and Reinforcement Learning for Enhanced Object Detection
Aug 13, 2024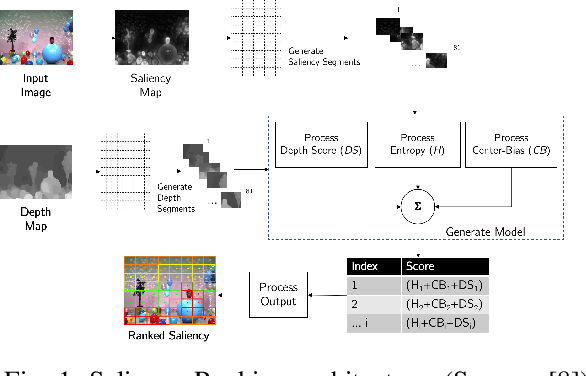
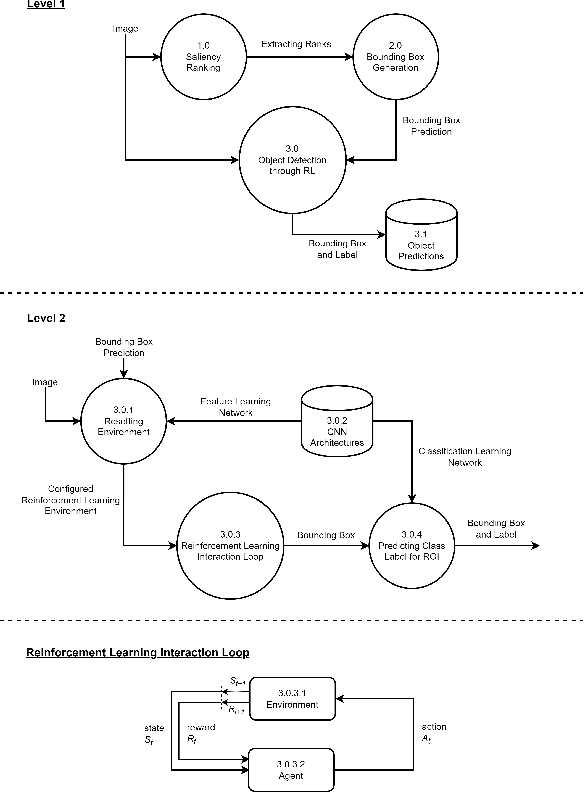

With the ever-growing variety of object detection approaches, this study explores a series of experiments that combine reinforcement learning (RL)-based visual attention methods with saliency ranking techniques to investigate transparent and sustainable solutions. By integrating saliency ranking for initial bounding box prediction and subsequently applying RL techniques to refine these predictions through a finite set of actions over multiple time steps, this study aims to enhance RL object detection accuracy. Presented as a series of experiments, this research investigates the use of various image feature extraction methods and explores diverse Deep Q-Network (DQN) architectural variations for deep reinforcement learning-based localisation agent training. Additionally, we focus on optimising the detection pipeline at every step by prioritising lightweight and faster models, while also incorporating the capability to classify detected objects, a feature absent in previous RL approaches. We show that by evaluating the performance of these trained agents using the Pascal VOC 2007 dataset, faster and more optimised models were developed. Notably, the best mean Average Precision (mAP) achieved in this study was 51.4, surpassing benchmarks set by RL-based single object detectors in the literature.
Deep Learning for Speaker Identification: Architectural Insights from AB-1 Corpus Analysis and Performance Evaluation
Aug 13, 2024In the fields of security systems, forensic investigations, and personalized services, the importance of speech as a fundamental human input outweighs text-based interactions. This research delves deeply into the complex field of Speaker Identification (SID), examining its essential components and emphasising Mel Spectrogram and Mel Frequency Cepstral Coefficients (MFCC) for feature extraction. Moreover, this study evaluates six slightly distinct model architectures using extensive analysis to evaluate their performance, with hyperparameter tuning applied to the best-performing model. This work performs a linguistic analysis to verify accent and gender accuracy, in addition to bias evaluation within the AB-1 Corpus dataset.