 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Saliency Ranking and Reinforcement Learning for Enhanced Object Detection
Paper and Code
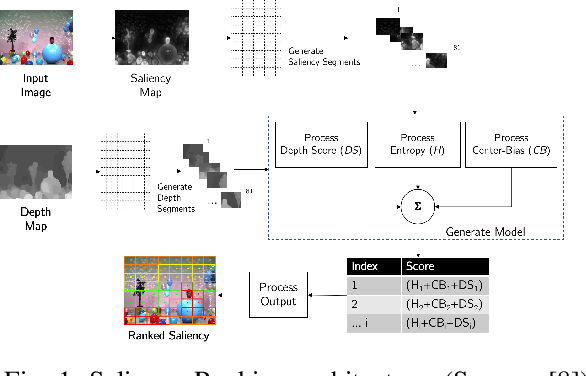
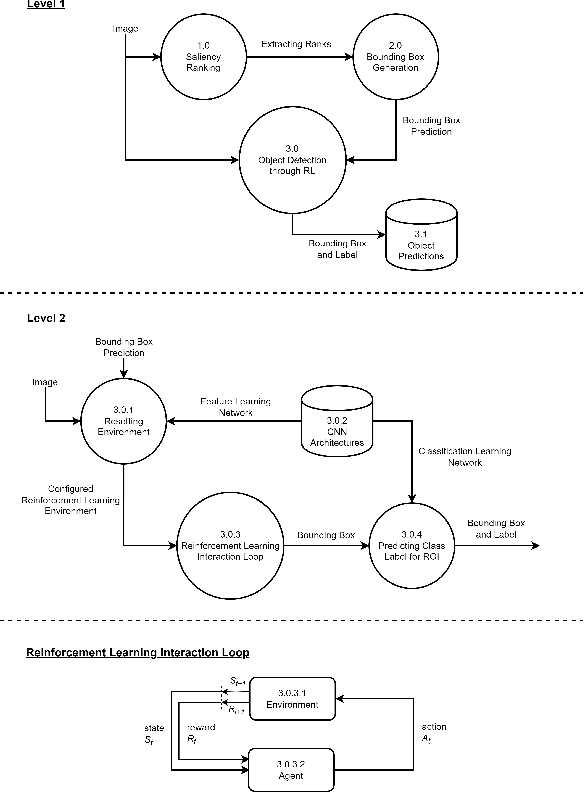

With the ever-growing variety of object detection approaches, this study explores a series of experiments that combine reinforcement learning (RL)-based visual attention methods with saliency ranking techniques to investigate transparent and sustainable solutions. By integrating saliency ranking for initial bounding box prediction and subsequently applying RL techniques to refine these predictions through a finite set of actions over multiple time steps, this study aims to enhance RL object detection accuracy. Presented as a series of experiments, this research investigates the use of various image feature extraction methods and explores diverse Deep Q-Network (DQN) architectural variations for deep reinforcement learning-based localisation agent training. Additionally, we focus on optimising the detection pipeline at every step by prioritising lightweight and faster models, while also incorporating the capability to classify detected objects, a feature absent in previous RL approaches. We show that by evaluating the performance of these trained agents using the Pascal VOC 2007 dataset, faster and more optimised models were developed. Notably, the best mean Average Precision (mAP) achieved in this study was 51.4, surpassing benchmarks set by RL-based single object detectors in the literature.