 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting heterogeneous diagnostic bias when developing clinical prediction models using causal hidden Markov models
May 07, 2026In routine care, individuals identified a priori as high-risk are usually tested for conditions more frequently. Protected attributes, such as sex or ethnicity may also determine testing frequency. Such heterogeneous detection rates across a population induce label error. This causes systematic model error for specific groups and biases performance metrics during validation. This paper proposes a method to correct for such bias in prediction models due to differential diagnostic delay. We use a causal inference framework to define our target estimand: an individual's diagnosis probability in a counterfactual scenario where their diagnosis rate matches that of a reference group. We model the longitudinal process as a hidden Markov model, in which confirmatory test results are emissions from a latent progressive disease stage. We validate our approach in simulated data and apply it to a case study of chronic kidney disease prediction using electronic health records. In simulations, our method reduces prediction bias and improves calibration-in-the-large, correcting the Observed:Expected ratio in the underdiagnosed group from 1.34 (standard deviation: 0.09) in a model developed without any correction for underdiagnosis bias to 1.02 (0.09). Violations of assumptions in the simulation affected the estimation of model parameters, but the proposed approach nonetheless remained better calibrated than the standard model. In the clinical case study, we identify diabetes as the main driver of observability, with an odds ratio of 10.36 (95% confidence interval, 9.80 - 11.02) in 6-month urine albumin-creatinine ratio testing rate. Using our approach to predict the counterfactual diagnostic rate in patients without diabetes, we improved the Observed:Expected ratio of a developed clinical prediction model from 1.55 (1.51 - 1.59) to 1.01 (0.98 - 1.04).
A Causal Framework for Mitigating Data Shifts in Healthcare
Mar 13, 2026Developing predictive models that perform reliably across diverse patient populations and heterogeneous environments is a core aim of medical research. However, generalization is only possible if the learned model is robust to statistical differences between data used for training and data seen at the time and place of deployment. Domain generalization methods provide strategies to address data shifts, but each method comes with its own set of assumptions and trade-offs. To apply these methods in healthcare, we must understand how domain shifts arise, what assumptions we prefer to make, and what our design constraints are. This article proposes a causal framework for the design of predictive models to improve generalization. Causality provides a powerful language to characterize and understand diverse domain shifts, regardless of data modality. This allows us to pinpoint why models fail to generalize, leading to more principled strategies to prepare for and adapt to shifts. We recommend general mitigation strategies, discussing trade-offs and highlighting existing work. Our causality-based perspective offers a critical foundation for developing robust, interpretable, and clinically relevant AI solutions in healthcare, paving the way for reliable real-world deployment.
Prediction of Survival Outcomes under Clinical Presence Shift: A Joint Neural Network Architecture
Aug 07, 2025Electronic health records arise from the complex interaction between patients and the healthcare system. This observation process of interactions, referred to as clinical presence, often impacts observed outcomes. When using electronic health records to develop clinical prediction models, it is standard practice to overlook clinical presence, impacting performance and limiting the transportability of models when this interaction evolves. We propose a multi-task recurrent neural network that jointly models the inter-observation time and the missingness processes characterising this interaction in parallel to the survival outcome of interest. Our work formalises the concept of clinical presence shift when the prediction model is deployed in new settings (e.g. different hospitals, regions or countries), and we theoretically justify why the proposed joint modelling can improve transportability under changes in clinical presence. We demonstrate, in a real-world mortality prediction task in the MIMIC-III dataset, how the proposed strategy improves performance and transportability compared to state-of-the-art prediction models that do not incorporate the observation process. These results emphasise the importance of leveraging clinical presence to improve performance and create more transportable clinical prediction models.
DeepJoint: Robust Survival Modelling Under Clinical Presence Shift
May 26, 2022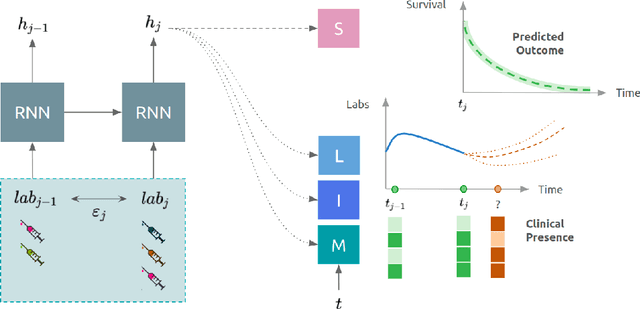
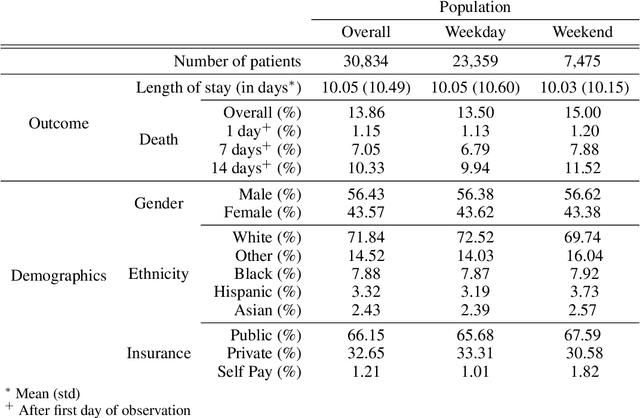
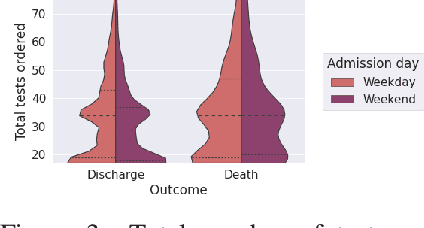
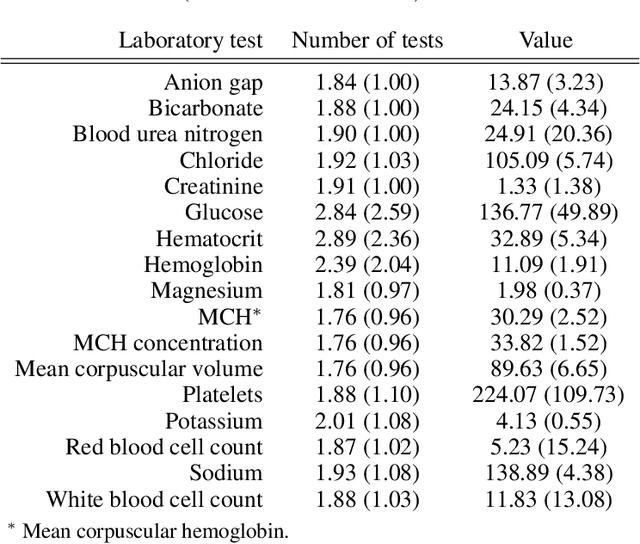
Observational data in medicine arise as a result of the complex interaction between patients and the healthcare system. The sampling process is often highly irregular and itself constitutes an informative process. When using such data to develop prediction models, this phenomenon is often ignored, leading to sub-optimal performance and generalisability of models when practices evolve. We propose a multi-task recurrent neural network which models three clinical presence dimensions -- namely the longitudinal, the inter-observation and the missingness processes -- in parallel to the survival outcome. On a prediction task using MIMIC III laboratory tests, explicit modelling of these three processes showed improved performance in comparison to state-of-the-art predictive models (C-index at 1 day horizon: 0.878). More importantly, the proposed approach was more robust to change in the clinical presence setting, demonstrated by performance comparison between patients admitted on weekdays and weekends. This analysis demonstrates the importance of studying and leveraging clinical presence to improve performance and create more transportable clinical models.
A systematic review of causal methods enabling predictions under hypothetical interventions
Nov 19, 2020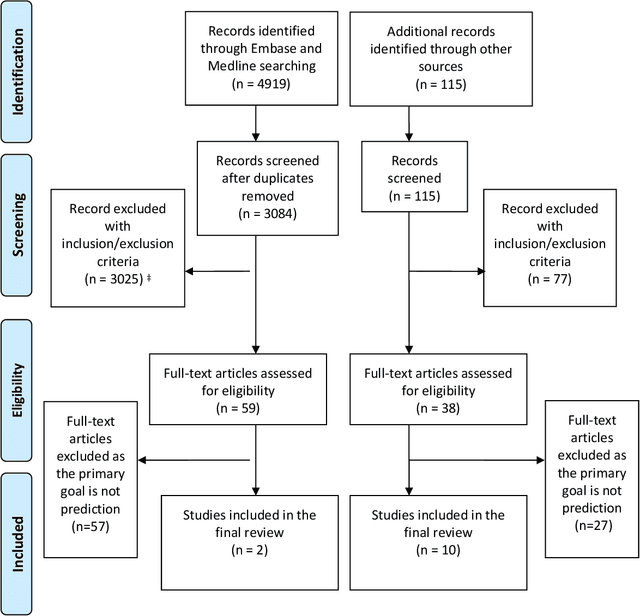
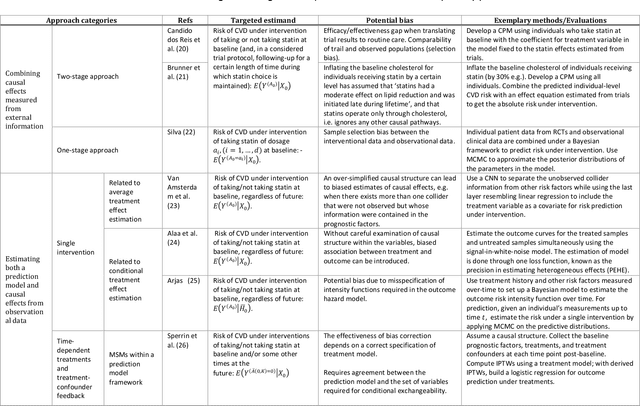
Background: The methods with which prediction models are usually developed mean that neither the parameters nor the predictions should be interpreted causally. For many applications this is perfectly acceptable. However, when prediction models are used to support decision making, there is often a need for predicting outcomes under hypothetical interventions. Aims: We aimed to identify and compare published methods for developing and validating prediction models that enable risk estimation of outcomes under hypothetical interventions, utilizing causal inference. We aimed to identify the main methodological approaches, their underlying assumptions, targeted estimands, and possible sources of bias. Finally, we aimed to highlight unresolved methodological challenges. Methods: We systematically reviewed literature published by December 2019, considering papers in the health domain that used causal considerations to enable prediction models to be used to evaluate predictions under hypothetical interventions. We included both methodology development studies and applied studies. Results: We identified 4919 papers through database searches and a further 115 papers through manual searches. Of these, 87 papers were retained for full text screening, of which 12 were selected for inclusion. We found papers from both the statistical and the machine learning literature. Most of the identified methods for causal inference from observational data were based on marginal structural models and g-estimation.