 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Generation of Dialogue Response Timings
May 18, 2020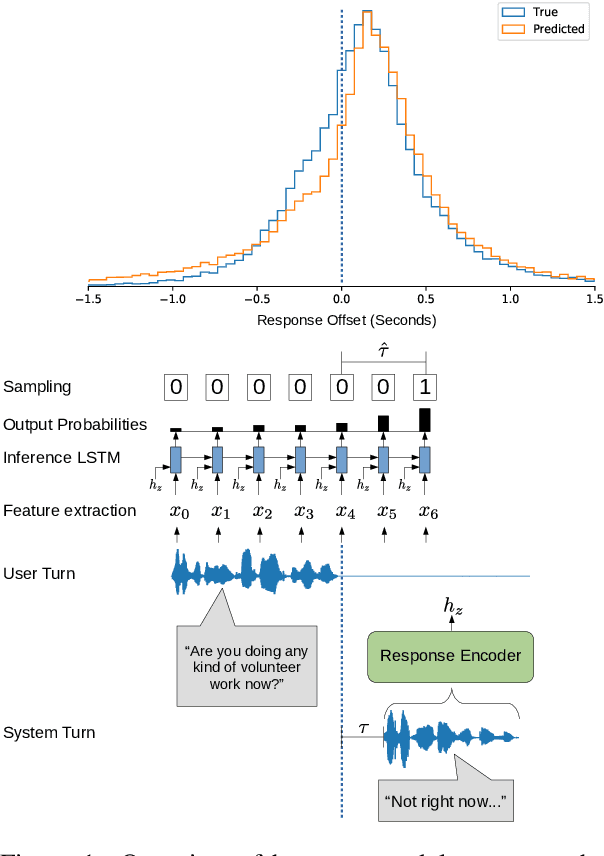


The timings of spoken response offsets in human dialogue have been shown to vary based on contextual elements of the dialogue. We propose neural models that simulate the distributions of these response offsets, taking into account the response turn as well as the preceding turn. The models are designed to be integrated into the pipeline of an incremental spoken dialogue system (SDS). We evaluate our models using offline experiments as well as human listening tests. We show that human listeners consider certain response timings to be more natural based on the dialogue context. The introduction of these models into SDS pipelines could increase the perceived naturalness of interactions.
Multimodal Continuous Turn-Taking Prediction Using Multiscale RNNs
Aug 31, 2018


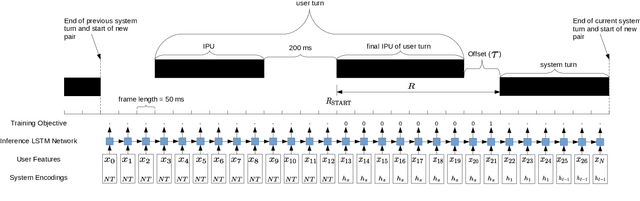
In human conversational interactions, turn-taking exchanges can be coordinated using cues from multiple modalities. To design spoken dialog systems that can conduct fluid interactions it is desirable to incorporate cues from separate modalities into turn-taking models. We propose that there is an appropriate temporal granularity at which modalities should be modeled. We design a multiscale RNN architecture to model modalities at separate timescales in a continuous manner. Our results show that modeling linguistic and acoustic features at separate temporal rates can be beneficial for turn-taking modeling. We also show that our approach can be used to incorporate gaze features into turn-taking models.
Investigating Speech Features for Continuous Turn-Taking Prediction Using LSTMs
Jun 29, 2018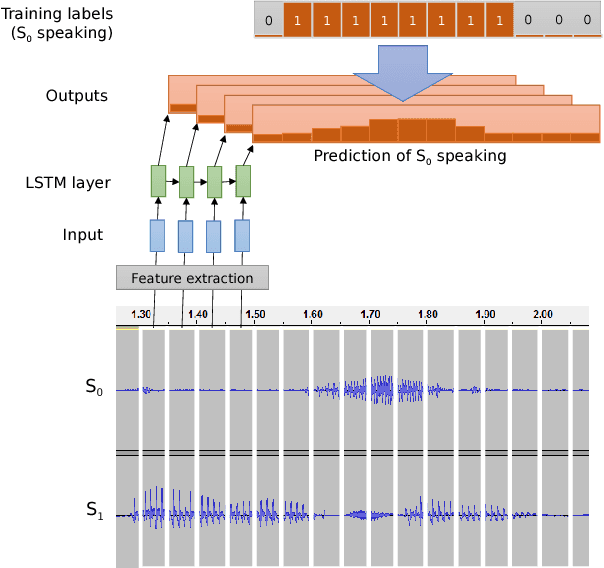

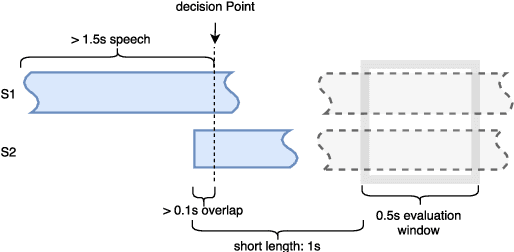
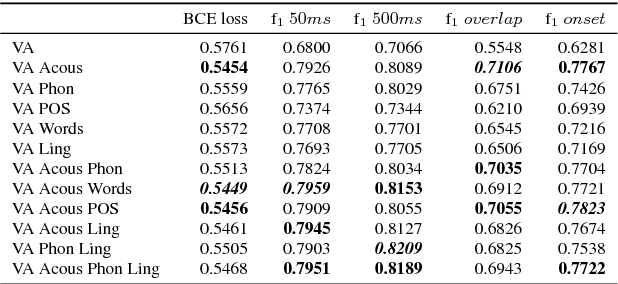
For spoken dialog systems to conduct fluid conversational interactions with users, the systems must be sensitive to turn-taking cues produced by a user. Models should be designed so that effective decisions can be made as to when it is appropriate, or not, for the system to speak. Traditional end-of-turn models, where decisions are made at utterance end-points, are limited in their ability to model fast turn-switches and overlap. A more flexible approach is to model turn-taking in a continuous manner using RNNs, where the system predicts speech probability scores for discrete frames within a future window. The continuous predictions represent generalized turn-taking behaviors observed in the training data and can be applied to make decisions that are not just limited to end-of-turn detection. In this paper, we investigate optimal speech-related feature sets for making predictions at pauses and overlaps in conversation. We find that while traditional acoustic features perform well, part-of-speech features generally perform worse than word features. We show that our current models outperform previously reported baselines.