 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector-Vector-Matrix Architecture: A Novel Hardware-Aware Framework for Low-Latency Inference in NLP Applications
Oct 06, 2020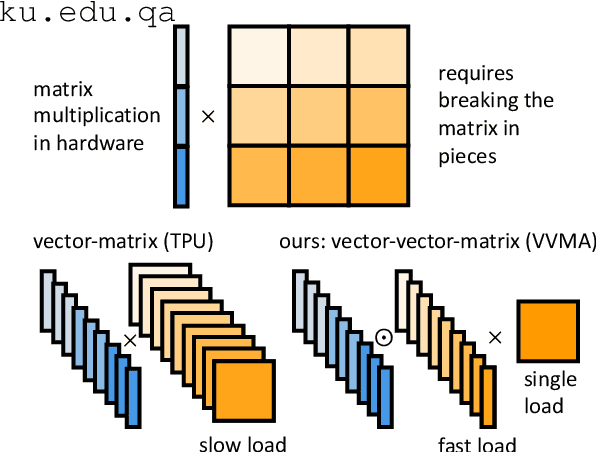
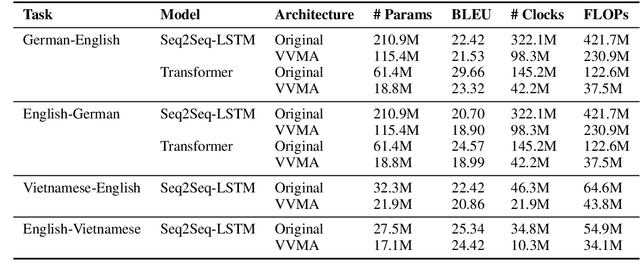
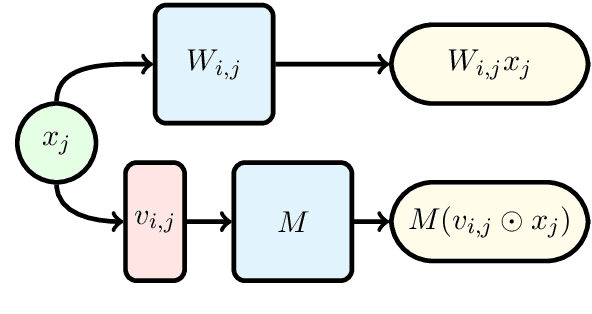
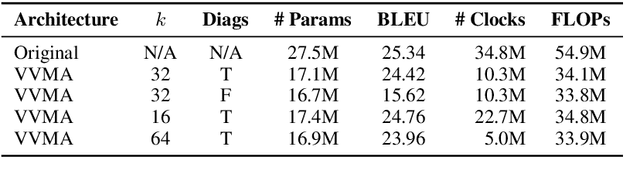
Deep neural networks have become the standard approach to building reliable Natural Language Processing (NLP) applications, ranging from Neural Machine Translation (NMT) to dialogue systems. However, improving accuracy by increasing the model size requires a large number of hardware computations, which can slow down NLP applications significantly at inference time. To address this issue, we propose a novel vector-vector-matrix architecture (VVMA), which greatly reduces the latency at inference time for NMT. This architecture takes advantage of specialized hardware that has low-latency vector-vector operations and higher-latency vector-matrix operations. It also reduces the number of parameters and FLOPs for virtually all models that rely on efficient matrix multipliers without significantly impacting accuracy. We present empirical results suggesting that our framework can reduce the latency of sequence-to-sequence and Transformer models used for NMT by a factor of four. Finally, we show evidence suggesting that our VVMA extends to other domains, and we discuss novel hardware for its efficient use.