 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pipeline of Augmentation and Sequence Embedding for Classification of Imbalanced Network Traffic
Feb 26, 2025Network Traffic Classification (NTC) is one of the most important tasks in network management. The imbalanced nature of classes on the internet presents a critical challenge in classification tasks. For example, some classes of applications are much more prevalent than others, such as HTTP. As a result, machine learning classification models do not perform well on those classes with fewer data. To address this problem, we propose a pipeline to balance the dataset and classify it using a robust and accurate embedding technique. First, we generate artificial data using Long Short-Term Memory (LSTM) networks and Kernel Density Estimation (KDE). Next, we propose replacing one-hot encoding for categorical features with a novel embedding framework based on the "Flow as a Sentence" perspective, which we name FS-Embedding. This framework treats the source and destination ports, along with the packet's direction, as one word in a flow, then trains an embedding vector space based on these new features through the learning classification task. Finally, we compare our pipeline with the training of a Convolutional Recurrent Neural Network (CRNN) and Transformers, both with imbalanced and sampled datasets, as well as with the one-hot encoding approach. We demonstrate that the proposed augmentation pipeline, combined with FS-Embedding, increases convergence speed and leads to a significant reduction in the number of model parameters, all while maintaining the same performance in terms of accuracy.
Privacy-Preserving Edge Federated Learning for Intelligent Mobile-Health Systems
May 09, 2024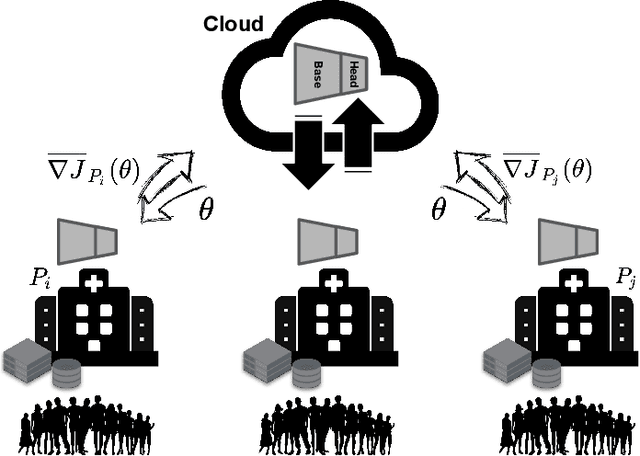
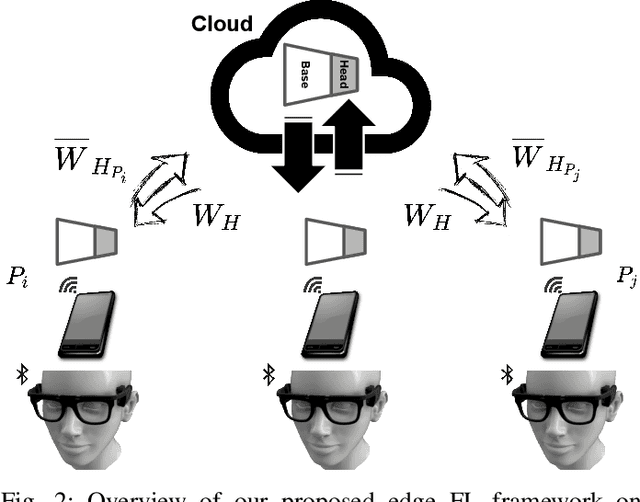


Machine Learning (ML) algorithms are generally designed for scenarios in which all data is stored in one data center, where the training is performed. However, in many applications, e.g., in the healthcare domain, the training data is distributed among several entities, e.g., different hospitals or patients' mobile devices/sensors. At the same time, transferring the data to a central location for learning is certainly not an option, due to privacy concerns and legal issues, and in certain cases, because of the communication and computation overheads. Federated Learning (FL) is the state-of-the-art collaborative ML approach for training an ML model across multiple parties holding local data samples, without sharing them. However, enabling learning from distributed data over such edge Internet of Things (IoT) systems (e.g., mobile-health and wearable technologies, involving sensitive personal/medical data) in a privacy-preserving fashion presents a major challenge mainly due to their stringent resource constraints, i.e., limited computing capacity, communication bandwidth, memory storage, and battery lifetime. In this paper, we propose a privacy-preserving edge FL framework for resource-constrained mobile-health and wearable technologies over the IoT infrastructure. We evaluate our proposed framework extensively and provide the implementation of our technique on Amazon's AWS cloud platform based on the seizure detection application in epilepsy monitoring using wearable technologies.
Augmentation Scheme for Dealing with Imbalanced Network Traffic Classification Using Deep Learning
Jan 01, 2019



One of the most important tasks in network management is identifying different types of traffic flows. As a result, a type of management service, called Network Traffic Classifier (NTC), has been introduced. One type of NTCs that has gained huge attention in recent years applies deep learning on packets in order to classify flows. Internet is an imbalanced environment i.e., some classes of applications are a lot more populated than others e.g., HTTP. Additionally, one of the challenges in deep learning methods is that they do not perform well in imbalanced environments in terms of evaluation metrics such as precision, recall, and $\mathrm{F_1}$ measure. In order to solve this problem, we recommend the use of augmentation methods to balance the dataset. In this paper, we propose a novel data augmentation approach based on the use of Long Short Term Memory (LSTM) networks for generating traffic flow patterns and Kernel Density Estimation (KDE) for replicating the numerical features of each class. First, we use the LSTM network in order to learn and generate the sequence of packets in a flow for classes with less population. Then, we complete the features of the sequence with generating random values based on the distribution of a certain feature, which will be estimated using KDE. Finally, we compare the training of a Convolutional Recurrent Neural Network (CRNN) in large-scale imbalanced, sampled, and augmented datasets. The contribution of our augmentation scheme is then evaluated on all of the datasets through measurements of precision, recall, and F1 measure for every class of application. The results demonstrate that our scheme is well suited for network traffic flow datasets and improves the performance of deep learning algorithms when it comes to above-mentioned metrics.