 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix cofactorization for joint spatial-spectral unmixing of hyperspectral images
Jul 19, 2019


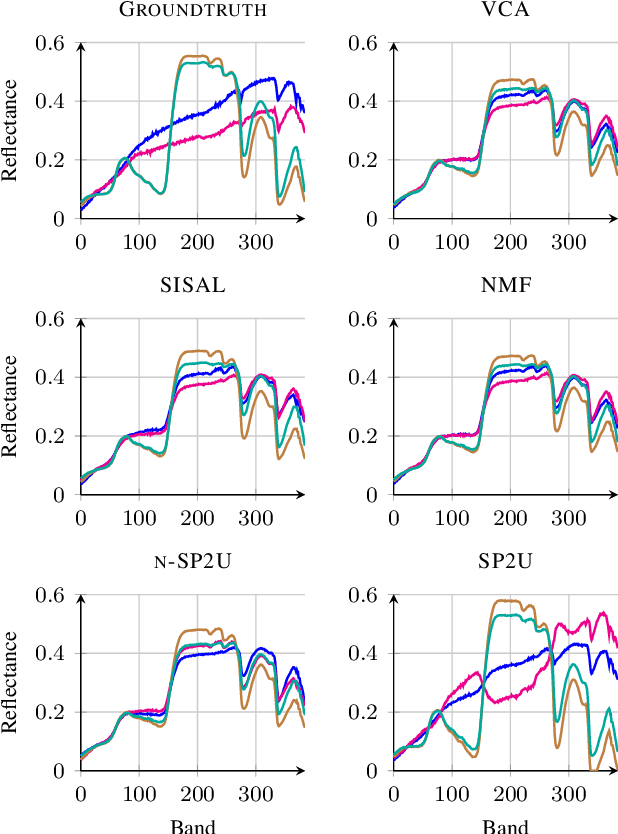
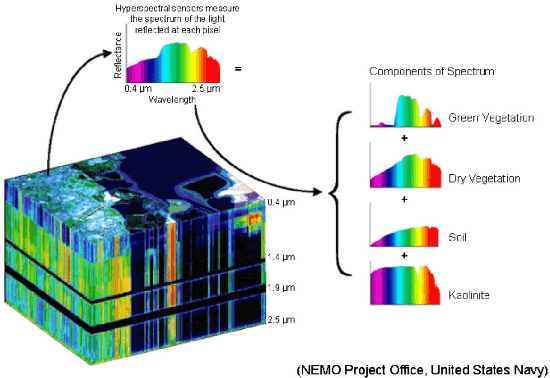
Hyperspectral unmixing aims at identifying a set of elementary spectra and the corresponding mixture coefficients for each pixel of an image. As the elementary spectra correspond to the reflectance spectra of real materials, they are often very correlated yielding an ill-conditioned problem. To enrich the model and to reduce ambiguity due to the high correlation, it is common to introduce spatial information to complement the spectral information. The most common way to introduce spatial information is to rely on a spatial regularization of the abundance maps. In this paper, instead of considering a simple but limited regularization process, spatial information is directly incorporated through the newly proposed context of spatial unmixing. Contextual features are extracted for each pixel and this additional set of observations is decomposed according to a linear model. Finally the spatial and spectral observations are unmixed jointly through a cofactorization model. In particular, this model introduces a coupling term used to identify clusters of shared spatial and spectral signatures. An evaluation of the proposed method is conducted on synthetic and real data and shows that results are accurate and also very meaningful since they describe both spatially and spectrally the various areas of the scene.
Matrix Cofactorization for Joint Representation Learning and Supervised Classification -- Application to Hyperspectral Image Analysis
Feb 07, 2019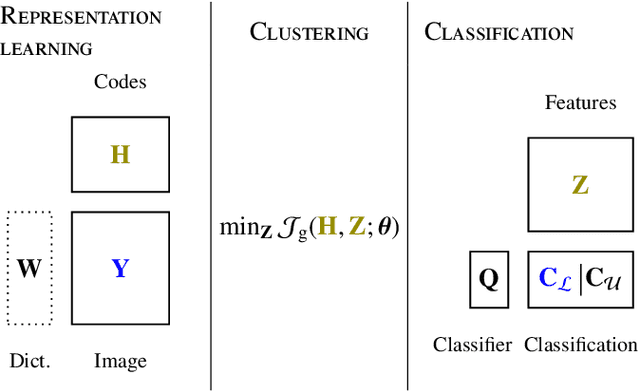
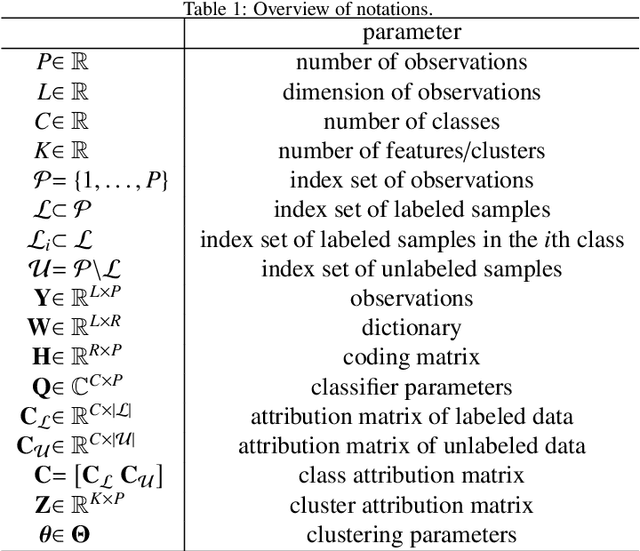
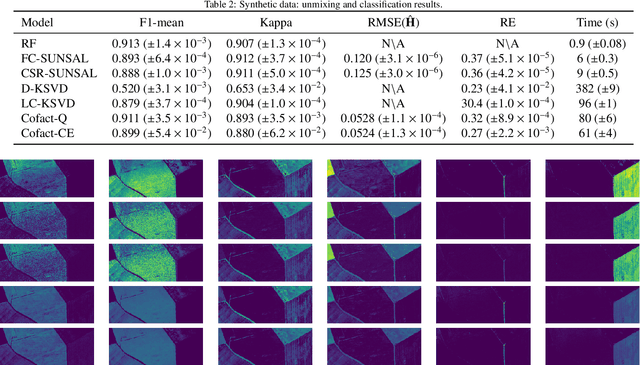
Supervised classification and representation learning are two widely used methods to analyze multivariate images. Although complementary, these two classes of methods have been scarcely considered jointly. In this paper, a method coupling these two approaches is designed using a matrix cofactorization formulation. Each task is modeled as a factorization matrix problem and a term relating both coding matrices is then introduced to drive an appropriate coupling. The link can be interpreted as a clustering operation over the low-dimensional representation vectors. The attribution vectors of the clustering are then used as features vectors for the classification task, i.e., the coding vectors of the corresponding factorization problem. A proximal gradient descent algorithm, ensuring convergence to a critical point of the objective function, is then derived to solve the resulting non-convex non-smooth optimization problem. An evaluation of the proposed method is finally conducted both on synthetic and real data in the specific context of hyperspectral image interpretation, unifying two standard analysis techniques, namely unmixing and classification.
Hyperspectral unmixing with spectral variability using adaptive bundles and double sparsity
Apr 30, 2018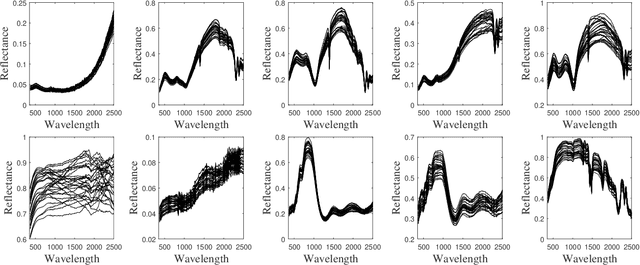

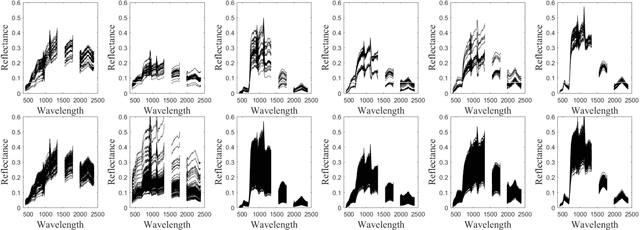
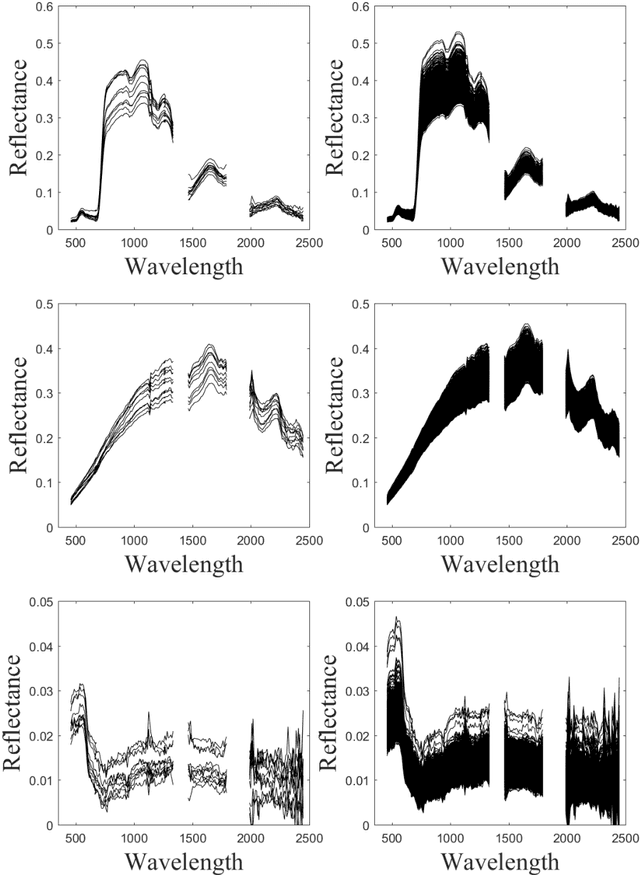
Spectral variability is one of the major issue when conducting hyperspectral unmixing. Within a given image composed of some elementary materials (herein referred to as endmember classes), the spectral signature characterizing these classes may spatially vary due to intrinsic component fluctuations or external factors (illumination). These redundant multiple endmember spectra within each class adversely affect the performance of unmixing methods. This paper proposes a mixing model that explicitly incorporates a hierarchical structure of redundant multiple spectra representing each class. The proposed method is designed to promote sparsity on the selection of both spectra and classes within each pixel. The resulting unmixing algorithm is able to adaptively recover several bundles of endmember spectra associated with each class and robustly estimate abundances. In addition, its flexibility allows a variable number of classes to be present within each pixel of the hyperspectral image to be unmixed. The proposed method is compared with other state-of-the-art unmixing methods that incorporate sparsity using both simulated and real hyperspectral data. The results show that the proposed method can successfully determine the variable number of classes present within each class and estimate the corresponding class abundances.
Hierarchical Bayesian image analysis: from low-level modeling to robust supervised learning
Dec 01, 2017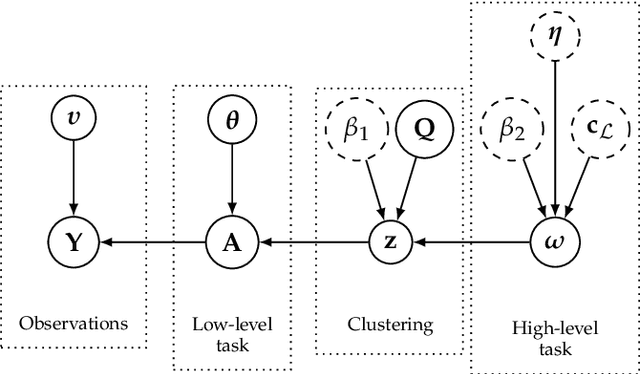
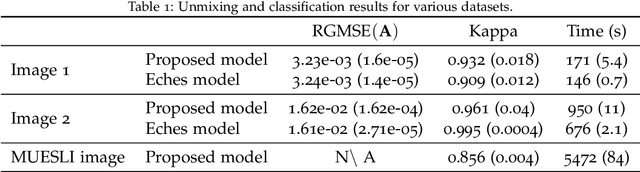

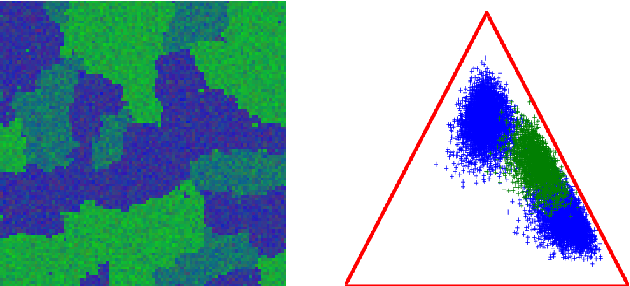
Within a supervised classification framework, labeled data are used to learn classifier parameters. Prior to that, it is generally required to perform dimensionality reduction via feature extraction. These preprocessing steps have motivated numerous research works aiming at recovering latent variables in an unsupervised context. This paper proposes a unified framework to perform classification and low-level modeling jointly. The main objective is to use the estimated latent variables as features for classification and to incorporate simultaneously supervised information to help latent variable extraction. The proposed hierarchical Bayesian model is divided into three stages: a first low-level modeling stage to estimate latent variables, a second stage clustering these features into statistically homogeneous groups and a last classification stage exploiting the (possibly badly) labeled data. Performance of the model is assessed in the specific context of hyperspectral image interpretation, unifying two standard analysis techniques, namely unmixing and classification.
Fast forward feature selection for the nonlinear classification of hyperspectral images
Jan 05, 2015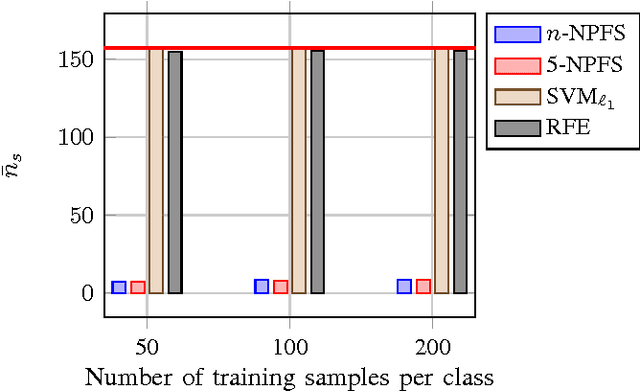
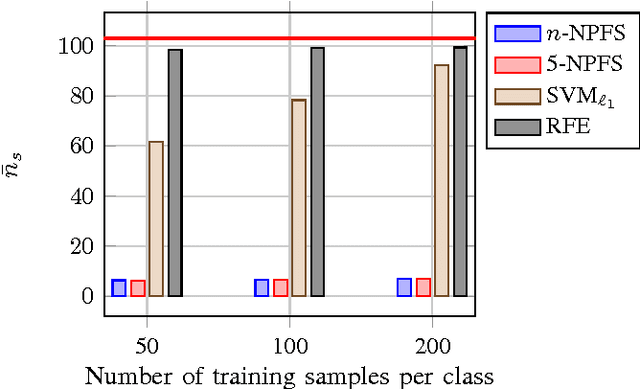
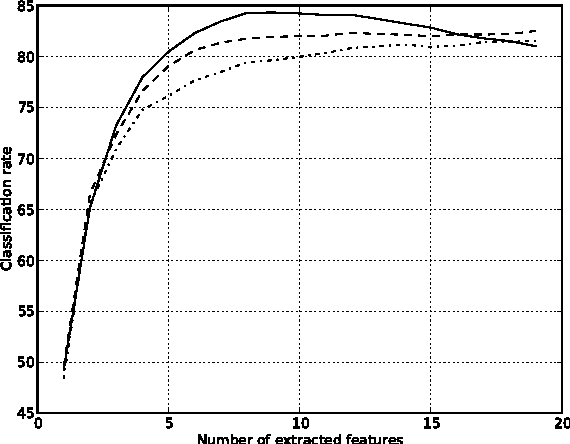
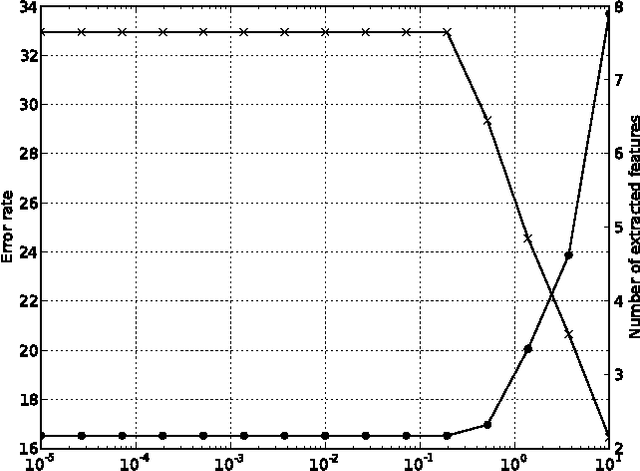
A fast forward feature selection algorithm is presented in this paper. It is based on a Gaussian mixture model (GMM) classifier. GMM are used for classifying hyperspectral images. The algorithm selects iteratively spectral features that maximizes an estimation of the classification rate. The estimation is done using the k-fold cross validation. In order to perform fast in terms of computing time, an efficient implementation is proposed. First, the GMM can be updated when the estimation of the classification rate is computed, rather than re-estimate the full model. Secondly, using marginalization of the GMM, sub models can be directly obtained from the full model learned with all the spectral features. Experimental results for two real hyperspectral data sets show that the method performs very well in terms of classification accuracy and processing time. Furthermore, the extracted model contains very few spectral channels.