 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInitial Study into Application of Feature Density and Linguistically-backed Embedding to Improve Machine Learning-based Cyberbullying Detection
Jun 04, 2022
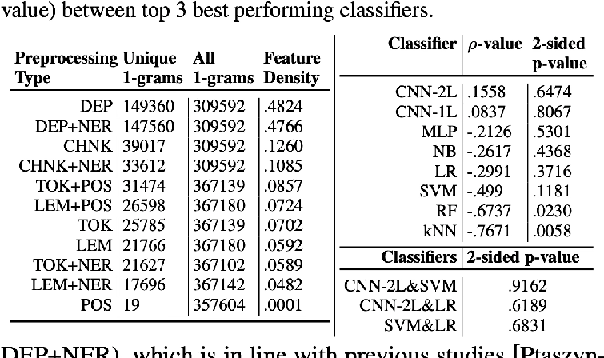
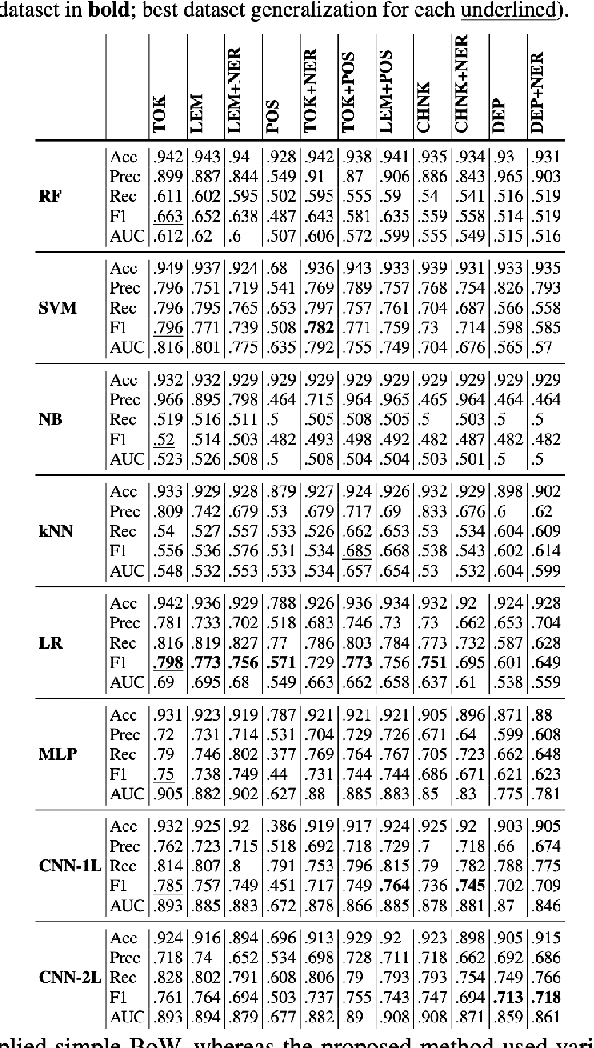
In this research, we study the change in the performance of machine learning (ML) classifiers when various linguistic preprocessing methods of a dataset were used, with the specific focus on linguistically-backed embeddings in Convolutional Neural Networks (CNN). Moreover, we study the concept of Feature Density and confirm its potential to comparatively predict the performance of ML classifiers, including CNN. The research was conducted on a Formspring dataset provided in a Kaggle competition on automatic cyberbullying detection. The dataset was re-annotated by objective experts (psychologists), as the importance of professional annotation in cyberbullying research has been indicated multiple times. The study confirmed the effectiveness of Neural Networks in cyberbullying detection and the correlation between classifier performance and Feature Density while also proposing a new approach of training various linguistically-backed embeddings for Convolutional Neural Networks.
Cyberbullying Detection -- Technical Report 2/2018, Department of Computer Science AGH, University of Science and Technology
Aug 02, 2018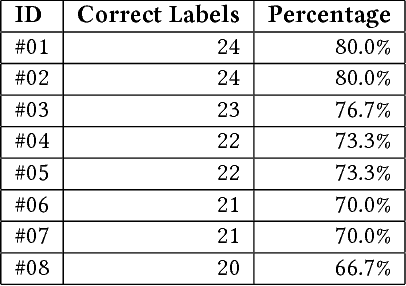
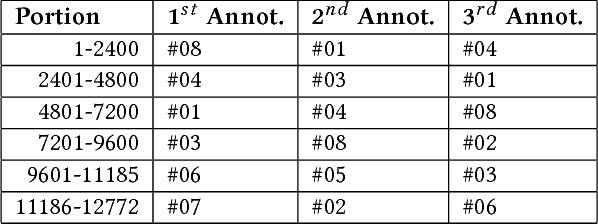
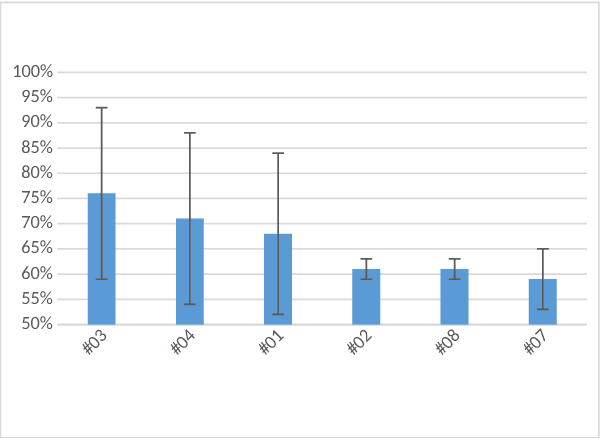
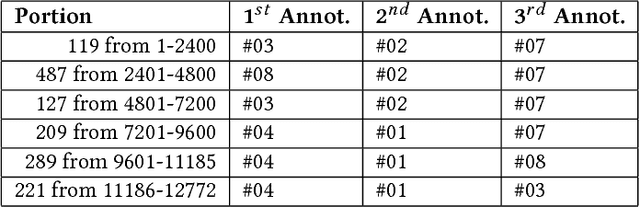
The research described in this paper concerns automatic cyberbullying detection in social media. There are two goals to achieve: building a gold standard cyberbullying detection dataset and measuring the performance of the Samurai cyberbullying detection system. The Formspring dataset provided in a Kaggle competition was re-annotated as a part of the research. The annotation procedure is described in detail and, unlike many other recent data annotation initiatives, does not use Mechanical Turk for finding people willing to perform the annotation. The new annotation compared to the old one seems to be more coherent since all tested cyberbullying detection system performed better on the former. The performance of the Samurai system is compared with 5 commercial systems and one well-known machine learning algorithm, used for classifying textual content, namely Fasttext. It turns out that Samurai scores the best in all measures (accuracy, precision and recall), while Fasttext is the second-best performing algorithm.