 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInitial Study into Application of Feature Density and Linguistically-backed Embedding to Improve Machine Learning-based Cyberbullying Detection
Paper and Code

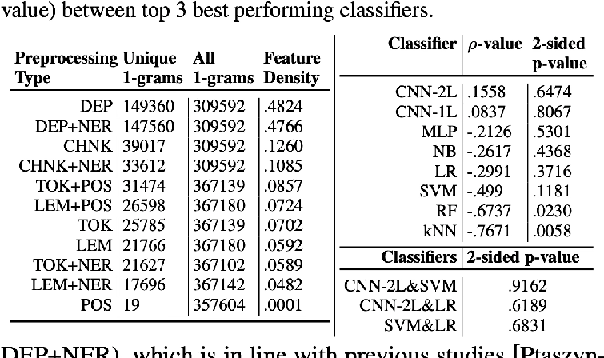
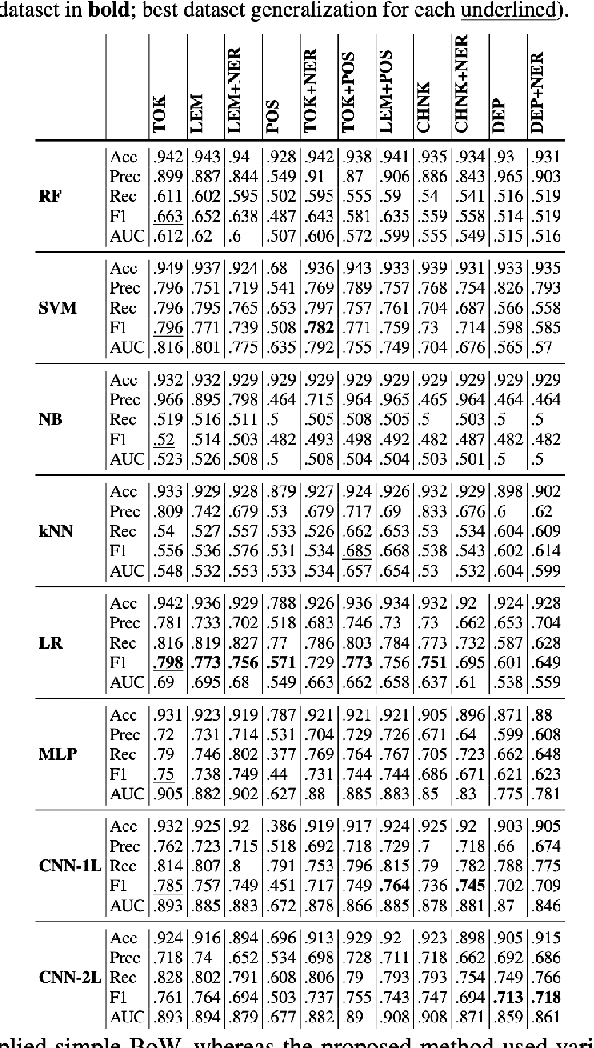
In this research, we study the change in the performance of machine learning (ML) classifiers when various linguistic preprocessing methods of a dataset were used, with the specific focus on linguistically-backed embeddings in Convolutional Neural Networks (CNN). Moreover, we study the concept of Feature Density and confirm its potential to comparatively predict the performance of ML classifiers, including CNN. The research was conducted on a Formspring dataset provided in a Kaggle competition on automatic cyberbullying detection. The dataset was re-annotated by objective experts (psychologists), as the importance of professional annotation in cyberbullying research has been indicated multiple times. The study confirmed the effectiveness of Neural Networks in cyberbullying detection and the correlation between classifier performance and Feature Density while also proposing a new approach of training various linguistically-backed embeddings for Convolutional Neural Networks.