 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Information Complexity and Randomization in Representation Learning
Feb 14, 2018

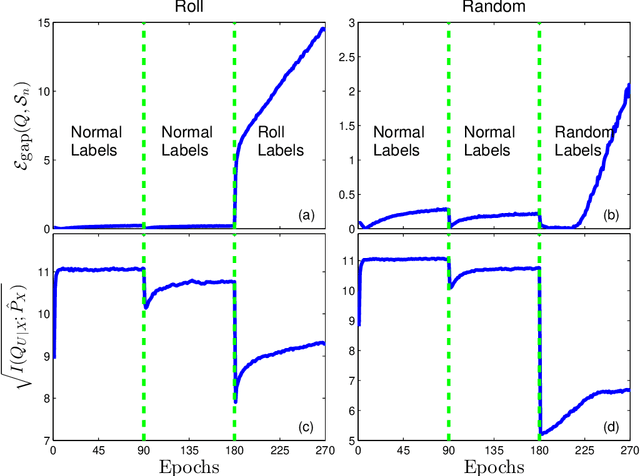
A grand challenge in representation learning is to learn the different explanatory factors of variation behind the high dimen- sional data. Encoder models are often determined to optimize performance on training data when the real objective is to generalize well to unseen data. Although there is enough numerical evidence suggesting that noise injection (during training) at the representation level might improve the generalization ability of encoders, an information-theoretic understanding of this principle remains elusive. This paper presents a sample-dependent bound on the generalization gap of the cross-entropy loss that scales with the information complexity (IC) of the representations, meaning the mutual information between inputs and their representations. The IC is empirically investigated for standard multi-layer neural networks with SGD on MNIST and CIFAR-10 datasets; the behaviour of the gap and the IC appear to be in direct correlation, suggesting that SGD selects encoders to implicitly minimize the IC. We specialize the IC to study the role of Dropout on the generalization capacity of deep encoders which is shown to be directly related to the encoder capacity, being a measure of the distinguishability among samples from their representations. Our results support some recent regularization methods.
Compression-Based Regularization with an Application to Multi-Task Learning
Nov 19, 2017


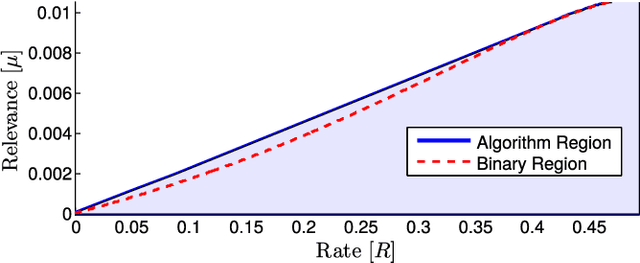
This paper investigates, from information theoretic grounds, a learning problem based on the principle that any regularity in a given dataset can be exploited to extract compact features from data, i.e., using fewer bits than needed to fully describe the data itself, in order to build meaningful representations of a relevant content (multiple labels). We begin by introducing the noisy lossy source coding paradigm with the log-loss fidelity criterion which provides the fundamental tradeoffs between the \emph{cross-entropy loss} (average risk) and the information rate of the features (model complexity). Our approach allows an information theoretic formulation of the \emph{multi-task learning} (MTL) problem which is a supervised learning framework in which the prediction models for several related tasks are learned jointly from common representations to achieve better generalization performance. Then, we present an iterative algorithm for computing the optimal tradeoffs and its global convergence is proven provided that some conditions hold. An important property of this algorithm is that it provides a natural safeguard against overfitting, because it minimizes the average risk taking into account a penalization induced by the model complexity. Remarkably, empirical results illustrate that there exists an optimal information rate minimizing the \emph{excess risk} which depends on the nature and the amount of available training data. An application to hierarchical text categorization is also investigated, extending previous works.
Collaborative Information Bottleneck
Nov 17, 2017
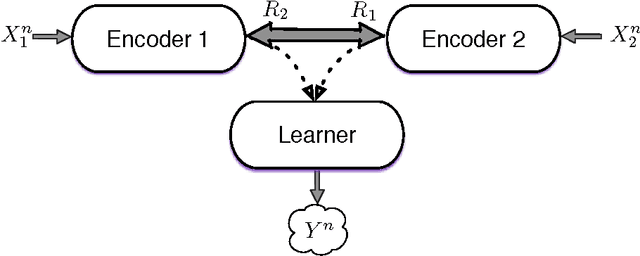
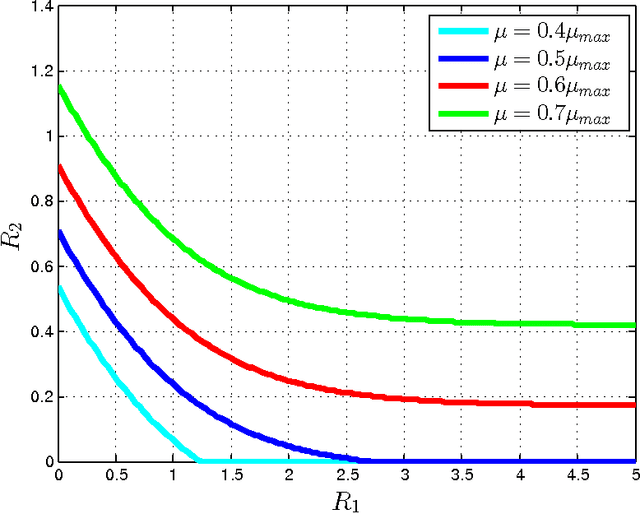
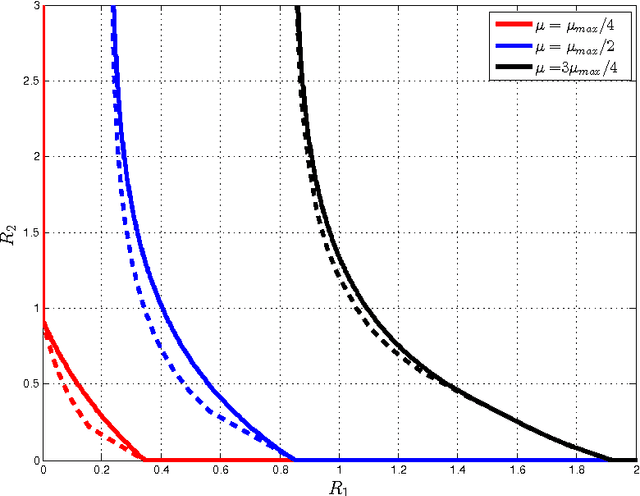
This paper investigates a multi-terminal source coding problem under a logarithmic loss fidelity which does not necessarily lead to an additive distortion measure. The problem is motivated by an extension of the Information Bottleneck method to a multi-source scenario where several encoders have to build cooperatively rate-limited descriptions of their sources in order to maximize information with respect to other unobserved (hidden) sources. More precisely, we study fundamental information-theoretic limits of the so-called: (i) Two-way Collaborative Information Bottleneck (TW-CIB) and (ii) the Collaborative Distributed Information Bottleneck (CDIB) problems. The TW-CIB problem consists of two distant encoders that separately observe marginal (dependent) components $X_1$ and $X_2$ and can cooperate through multiple exchanges of limited information with the aim of extracting information about hidden variables $(Y_1,Y_2)$, which can be arbitrarily dependent on $(X_1,X_2)$. On the other hand, in CDIB there are two cooperating encoders which separately observe $X_1$ and $X_2$ and a third node which can listen to the exchanges between the two encoders in order to obtain information about a hidden variable $Y$. The relevance (figure-of-merit) is measured in terms of a normalized (per-sample) multi-letter mutual information metric (log-loss fidelity) and an interesting tradeoff arises by constraining the complexity of descriptions, measured in terms of the rates needed for the exchanges between the encoders and decoders involved. Inner and outer bounds to the complexity-relevance region of these problems are derived from which optimality is characterized for several cases of interest. Our resulting theoretical complexity-relevance regions are finally evaluated for binary symmetric and Gaussian statistical models.