 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersian-WSD-Corpus: A Sense Annotated Corpus for Persian All-words Word Sense Disambiguation
Jul 04, 2021

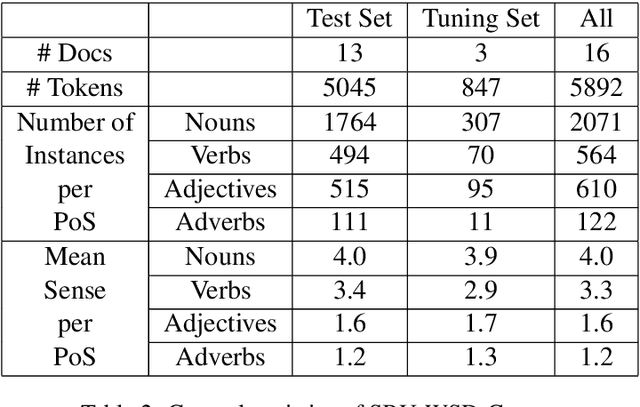
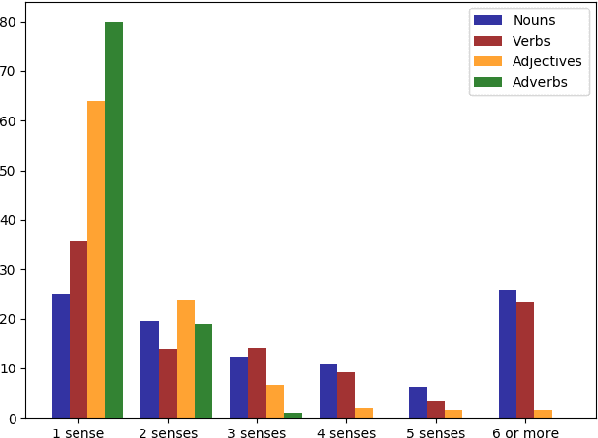
Word Sense Disambiguation (WSD) is a long-standing task in Natural Language Processing(NLP) that aims to automatically identify the most relevant meaning of the words in a given context. Developing standard WSD test collections can be mentioned as an important prerequisite for developing and evaluating different WSD systems in the language of interest. Although many WSD test collections have been developed for a variety of languages, no standard All-words WSD benchmark is available for Persian. In this paper, we address this shortage for the Persian language by introducing SBU-WSD-Corpus, as the first standard test set for the Persian All-words WSD task. SBU-WSD-Corpus is manually annotated with senses from the Persian WordNet (FarsNet) sense inventory. To this end, three annotators used SAMP (a tool for sense annotation based on FarsNet lexical graph) to perform the annotation task. SBU-WSD-Corpus consists of 19 Persian documents in different domains such as Sports, Science, Arts, etc. It includes 5892 content words of Persian running text and 3371 manually sense annotated words (2073 nouns, 566 verbs, 610 adjectives, and 122 adverbs). Providing baselines for future studies on the Persian All-words WSD task, we evaluate several WSD models on SBU-WSD-Corpus. The corpus is publicly available at https://github.com/hrouhizadeh/SBU-WSD-Corpus.