 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum Description Length Principle in Supervised Learning with Application to Lasso
Jul 11, 2016
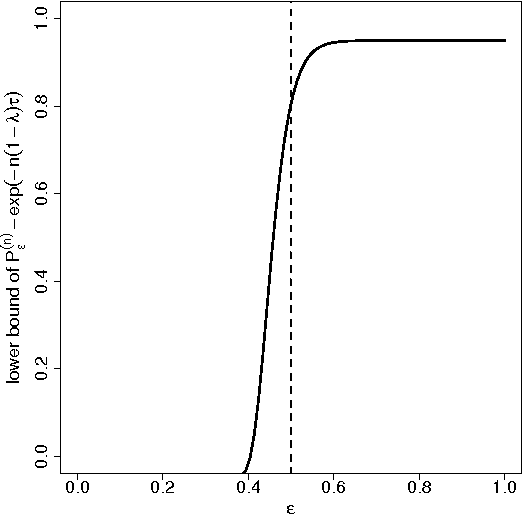


The minimum description length (MDL) principle in supervised learning is studied. One of the most important theories for the MDL principle is Barron and Cover's theory (BC theory), which gives a mathematical justification of the MDL principle. The original BC theory, however, can be applied to supervised learning only approximately and limitedly. Though Barron et al. recently succeeded in removing a similar approximation in case of unsupervised learning, their idea cannot be essentially applied to supervised learning in general. To overcome this issue, an extension of BC theory to supervised learning is proposed. The derived risk bound has several advantages inherited from the original BC theory. First, the risk bound holds for finite sample size. Second, it requires remarkably few assumptions. Third, the risk bound has a form of redundancy of the two-stage code for the MDL procedure. Hence, the proposed extension gives a mathematical justification of the MDL principle to supervised learning like the original BC theory. As an important example of application, new risk and (probabilistic) regret bounds of lasso with random design are derived. The derived risk bound holds for any finite sample size $n$ and feature number $p$ even if $n\ll p$ without boundedness of features in contrast to the past work. Behavior of the regret bound is investigated by numerical simulations. We believe that this is the first extension of BC theory to general supervised learning with random design without approximation.
Semi-Supervised learning with Density-Ratio Estimation
Apr 18, 2012


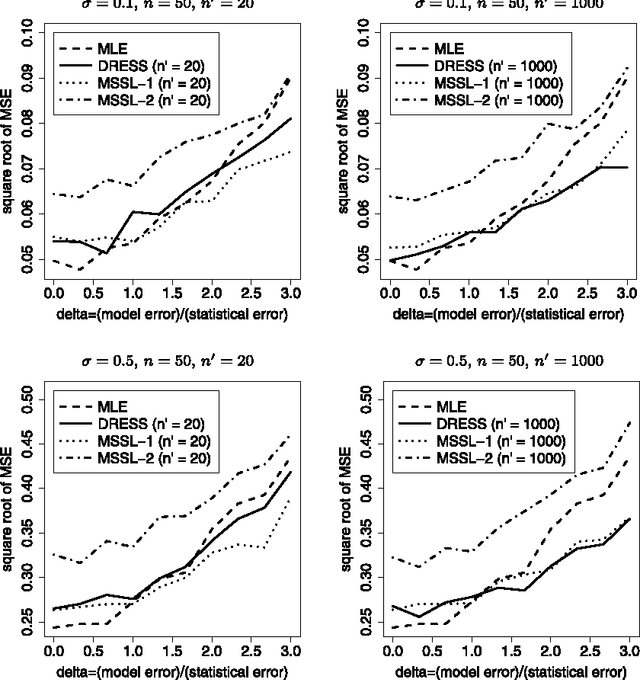
In this paper, we study statistical properties of semi-supervised learning, which is considered as an important problem in the community of machine learning. In the standard supervised learning, only the labeled data is observed. The classification and regression problems are formalized as the supervised learning. In semi-supervised learning, unlabeled data is also obtained in addition to labeled data. Hence, exploiting unlabeled data is important to improve the prediction accuracy in semi-supervised learning. This problems is regarded as a semiparametric estimation problem with missing data. Under the the discriminative probabilistic models, it had been considered that the unlabeled data is useless to improve the estimation accuracy. Recently, it was revealed that the weighted estimator using the unlabeled data achieves better prediction accuracy in comparison to the learning method using only labeled data, especially when the discriminative probabilistic model is misspecified. That is, the improvement under the semiparametric model with missing data is possible, when the semiparametric model is misspecified. In this paper, we apply the density-ratio estimator to obtain the weight function in the semi-supervised learning. The benefit of our approach is that the proposed estimator does not require well-specified probabilistic models for the probability of the unlabeled data. Based on the statistical asymptotic theory, we prove that the estimation accuracy of our method outperforms the supervised learning using only labeled data. Some numerical experiments present the usefulness of our methods.