 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised learning with Density-Ratio Estimation
Paper and Code
Apr 18, 2012


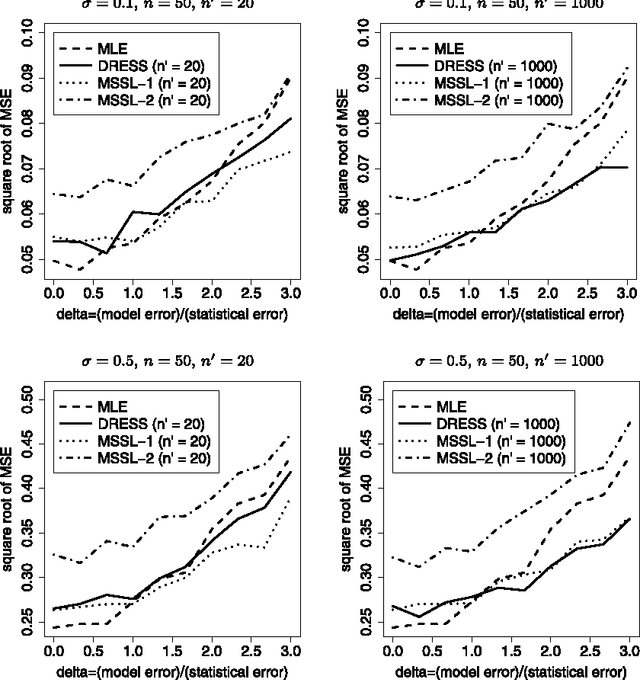
In this paper, we study statistical properties of semi-supervised learning, which is considered as an important problem in the community of machine learning. In the standard supervised learning, only the labeled data is observed. The classification and regression problems are formalized as the supervised learning. In semi-supervised learning, unlabeled data is also obtained in addition to labeled data. Hence, exploiting unlabeled data is important to improve the prediction accuracy in semi-supervised learning. This problems is regarded as a semiparametric estimation problem with missing data. Under the the discriminative probabilistic models, it had been considered that the unlabeled data is useless to improve the estimation accuracy. Recently, it was revealed that the weighted estimator using the unlabeled data achieves better prediction accuracy in comparison to the learning method using only labeled data, especially when the discriminative probabilistic model is misspecified. That is, the improvement under the semiparametric model with missing data is possible, when the semiparametric model is misspecified. In this paper, we apply the density-ratio estimator to obtain the weight function in the semi-supervised learning. The benefit of our approach is that the proposed estimator does not require well-specified probabilistic models for the probability of the unlabeled data. Based on the statistical asymptotic theory, we prove that the estimation accuracy of our method outperforms the supervised learning using only labeled data. Some numerical experiments present the usefulness of our methods.