 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassical Music Generation in Distinct Dastgahs with AlimNet ACGAN
Jan 15, 2019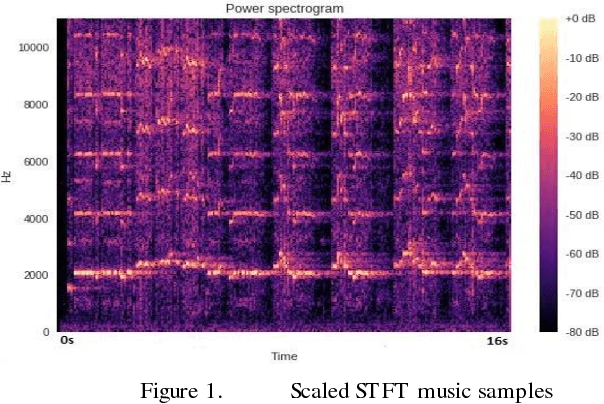
In this paper AlimNet (With respect to great musician, Alim Qasimov) an auxiliary generative adversarial deep neural network (ACGAN) for generating music categorically, is used. This proposed network is a conditional ACGAN to condition the generation process on music tracks which has a hybrid architecture, composing of different kind of layers of neural networks. The employed music dataset is MICM which contains 1137 music samples (506 violins and 631 straw) with seven types of classical music Dastgah labels. To extract both temporal and spectral features, Short-Time Fourier Transform (STFT) is applied to convert input audio signals from time domain to time-frequency domain. GANs are composed of a generator for generating new samples and a discriminator to help generator making better samples. Samples in time-frequency domain are used to train discriminator in fourteen classes (seven Dastgahs and two instruments). The outputs of the conditional ACGAN are also artificial music samples in those mentioned scales in time-frequency domain. Then the output of the generator is transformed by Inverse STFT (ISTFT). Finally, randomly ten generated music samples (five violin and five straw samples) are given to ten musicians to rate how exact the samples are and the overall result was 76.5%.
Instrument-Independent Dastgah Recognition of Iranian Classical Music Using AzarNet
Jan 09, 2019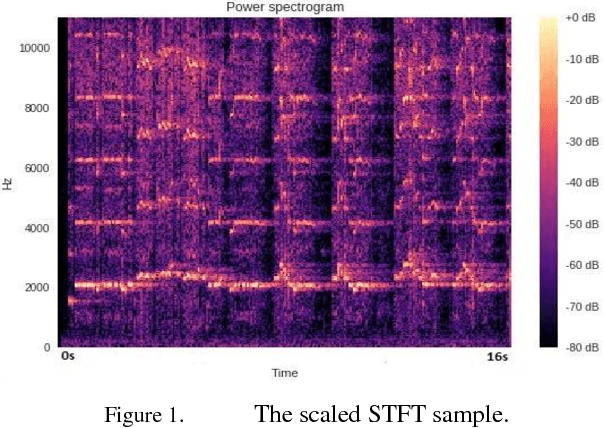
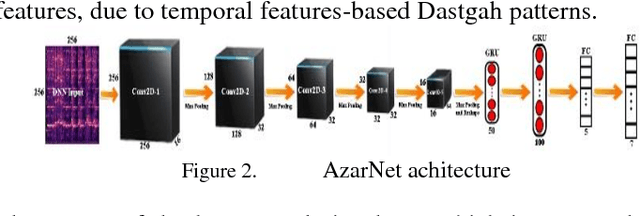
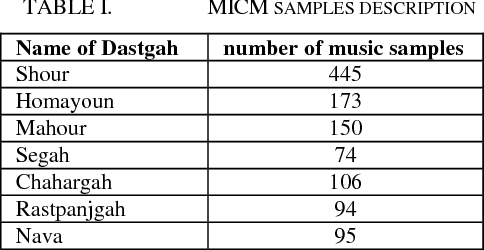
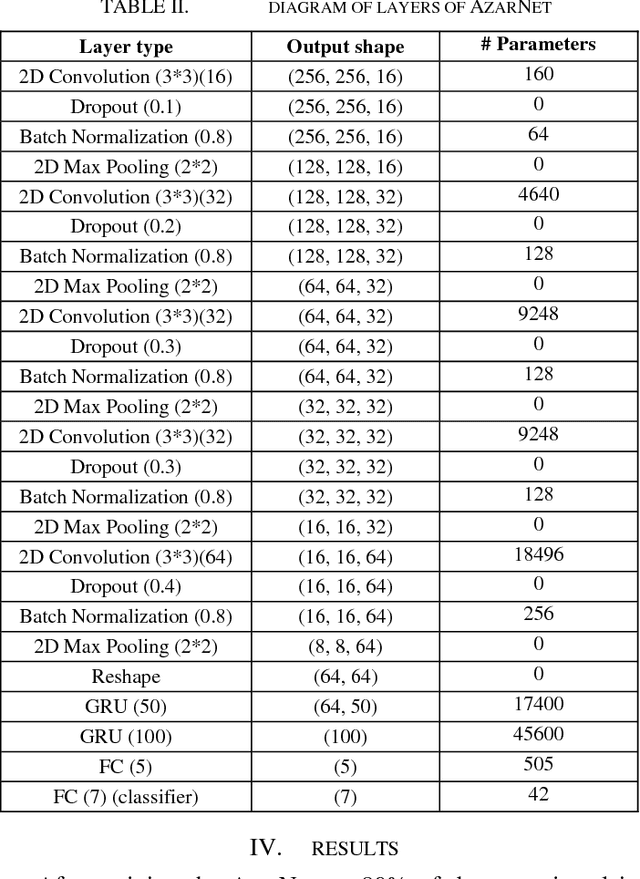
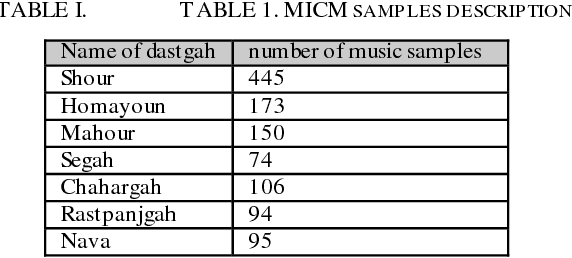
In this paper, AzarNet, a deep neural network (DNN), is proposed to recognizing seven different Dastgahs of Iranian classical music in Maryam Iranian classical music (MICM) dataset. Over the last years, there has been remarkable interest in employing feature learning and DNNs which lead to decreasing the required engineering effort. DNNs have shown better performance in many classification tasks such as audio signal classification compares to shallow processing architectures. Despite image data, audio data need some preprocessing steps to extract spectra and temporal features. Some transformations like Short-Time Fourier Transform (STFT) have been used in the state of art researches to transform audio signals from time-domain to time-frequency domain to extract both temporal and spectra features. In this research, the STFT output results which are extracted features are given to AzarNet for learning and classification processes. It is worth noting that, the mentioned dataset contains music tracks composed with two instruments (violin and straw). The overall f1 score of AzarNet on test set, for average of all seven classes was 86.21% which is the best result ever reported in Dastgah classification according to our best knowledge.