 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Approximation for Fair Correlation Clustering
Jun 09, 2022
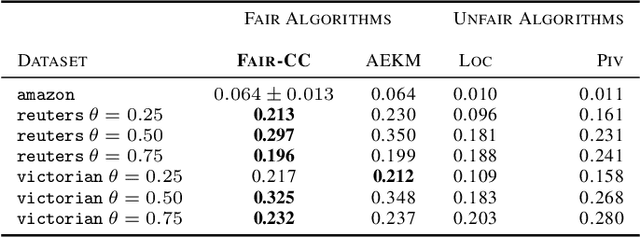
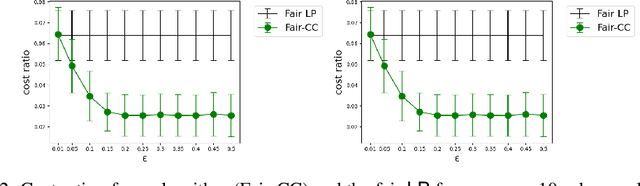
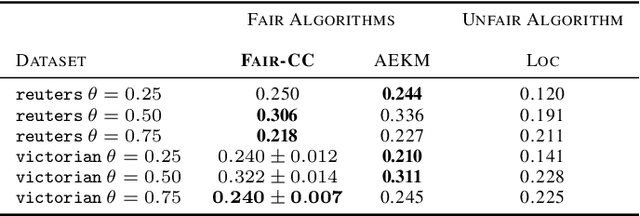
Correlation clustering is a ubiquitous paradigm in unsupervised machine learning where addressing unfairness is a major challenge. Motivated by this, we study Fair Correlation Clustering where the data points may belong to different protected groups and the goal is to ensure fair representation of all groups across clusters. Our paper significantly generalizes and improves on the quality guarantees of previous work of Ahmadi et al. and Ahmadian et al. as follows. - We allow the user to specify an arbitrary upper bound on the representation of each group in a cluster. - Our algorithm allows individuals to have multiple protected features and ensure fairness simultaneously across them all. - We prove guarantees for clustering quality and fairness in this general setting. Furthermore, this improves on the results for the special cases studied in previous work. Our experiments on real-world data demonstrate that our clustering quality compared to the optimal solution is much better than what our theoretical result suggests.
Better Algorithms for Individually Fair $k$-Clustering
Jun 23, 2021



We study data clustering problems with $\ell_p$-norm objectives (e.g. $k$-Median and $k$-Means) in the context of individual fairness. The dataset consists of $n$ points, and we want to find $k$ centers such that (a) the objective is minimized, while (b) respecting the individual fairness constraint that every point $v$ has a center within a distance at most $r(v)$, where $r(v)$ is $v$'s distance to its $(n/k)$th nearest point. Jung, Kannan, and Lutz [FORC 2020] introduced this concept and designed a clustering algorithm with provable (approximate) fairness and objective guarantees for the $\ell_\infty$ or $k$-Center objective. Mahabadi and Vakilian [ICML 2020] revisited this problem to give a local-search algorithm for all $\ell_p$-norms. Empirically, their algorithms outperform Jung et. al.'s by a large margin in terms of cost (for $k$-Median and $k$-Means), but they incur a reasonable loss in fairness. In this paper, our main contribution is to use Linear Programming (LP) techniques to obtain better algorithms for this problem, both in theory and in practice. We prove that by modifying known LP rounding techniques, one gets a worst-case guarantee on the objective which is much better than in MV20, and empirically, this objective is extremely close to the optimal. Furthermore, our theoretical fairness guarantees are comparable with MV20 in theory, and empirically, we obtain noticeably fairer solutions. Although solving the LP {\em exactly} might be prohibitive, we demonstrate that in practice, a simple sparsification technique drastically improves the run-time of our algorithm.
Revisiting Priority $k$-Center: Fairness and Outliers
Mar 04, 2021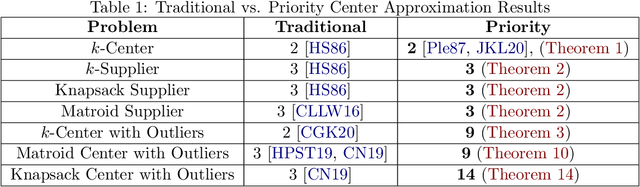
In the Priority $k$-Center problem, the input consists of a metric space $(X,d)$, an integer $k$ and for each point $v \in X$ a priority radius $r(v)$. The goal is to choose $k$-centers $S \subseteq X$ to minimize $\max_{v \in X} \frac{1}{r(v)} d(v,S)$. If all $r(v)$'s were uniform, one obtains the classical $k$-center problem. Plesn\'ik [Plesn\'ik, Disc. Appl. Math. 1987] introduced this problem and gave a $2$-approximation algorithm matching the best possible algorithm for vanilla $k$-center. We show how the problem is related to two different notions of fair clustering [Harris et al., NeurIPS 2018; Jung et al., FORC 2020]. Motivated by these developments we revisit the problem and, in our main technical contribution, develop a framework that yields constant factor approximation algorithms for Priority $k$-Center with outliers. Our framework extends to generalizations of Priority $k$-Center to matroid and knapsack constraints, and as a corollary, also yields algorithms with fairness guarantees in the lottery model of Harris et al.
Fair Algorithms for Clustering
Jan 08, 2019
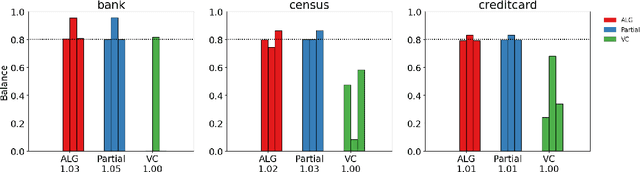
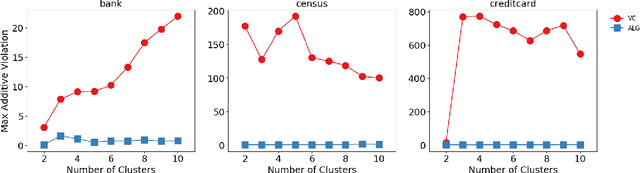

We study clustering problems under the lens of {\em algorithmic fairness} inspired by the disparate impact doctrine. Given a collection of points containing many {\em protected groups}, the goal is to find good clustering solutions where each cluster {\em fairly represents} each group. We allow the user to specify the parameters that define fair representation, and this flexibility makes our model significantly more general than the recent models of Chierichetti et al. (NIPS 2017) and R\"osner and Schmidt (ICALP 2018). Our main result is a simple algorithm that, for any $\ell_p$-norm including the $k$-center, $k$-median, and $k$-means objectives, transforms any clustering solution to a fair one with only a slight loss in quality.