Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Algorithms for Clustering
Paper and Code

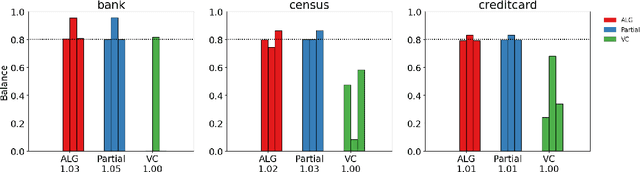
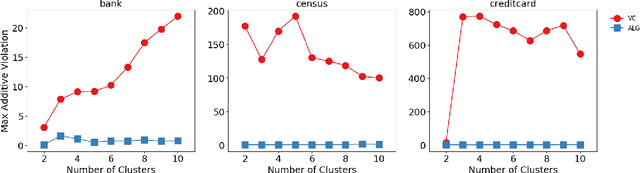

We study clustering problems under the lens of {\em algorithmic fairness} inspired by the disparate impact doctrine. Given a collection of points containing many {\em protected groups}, the goal is to find good clustering solutions where each cluster {\em fairly represents} each group. We allow the user to specify the parameters that define fair representation, and this flexibility makes our model significantly more general than the recent models of Chierichetti et al. (NIPS 2017) and R\"osner and Schmidt (ICALP 2018). Our main result is a simple algorithm that, for any $\ell_p$-norm including the $k$-center, $k$-median, and $k$-means objectives, transforms any clustering solution to a fair one with only a slight loss in quality.
View paper on