 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Approximation for Fair Correlation Clustering
Paper and Code
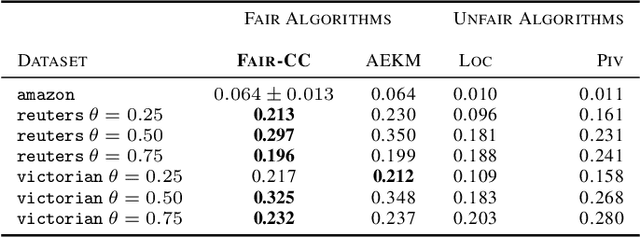
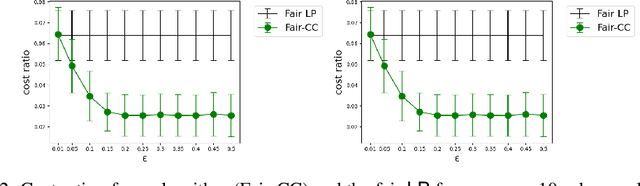
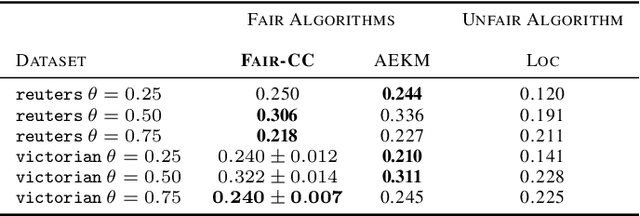
Correlation clustering is a ubiquitous paradigm in unsupervised machine learning where addressing unfairness is a major challenge. Motivated by this, we study Fair Correlation Clustering where the data points may belong to different protected groups and the goal is to ensure fair representation of all groups across clusters. Our paper significantly generalizes and improves on the quality guarantees of previous work of Ahmadi et al. and Ahmadian et al. as follows. - We allow the user to specify an arbitrary upper bound on the representation of each group in a cluster. - Our algorithm allows individuals to have multiple protected features and ensure fairness simultaneously across them all. - We prove guarantees for clustering quality and fairness in this general setting. Furthermore, this improves on the results for the special cases studied in previous work. Our experiments on real-world data demonstrate that our clustering quality compared to the optimal solution is much better than what our theoretical result suggests.