 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Antisocial Behavior Detection on Twitter
Dec 28, 2023Social media resurgence of antisocial behavior has exerted a downward spiral on stereotypical beliefs, and hateful comments towards individuals and social groups, as well as false or distorted news. The advances in graph neural networks employed on massive quantities of graph-structured data raise high hopes for the future of mediating communication on social media platforms. An approach based on graph convolutional data was employed to better capture the dependencies between the heterogeneous types of data. Utilizing past and present experiences on the topic, we proposed and evaluated a graph-based approach for antisocial behavior detection, with general applicability that is both language- and context-independent. In this research, we carried out an experimental validation of our graph-based approach on several PAN datasets provided as part of their shared tasks, that enable the discussion of the results obtained by the proposed solution.
A Review of Text Style Transfer using Deep Learning
Sep 30, 2021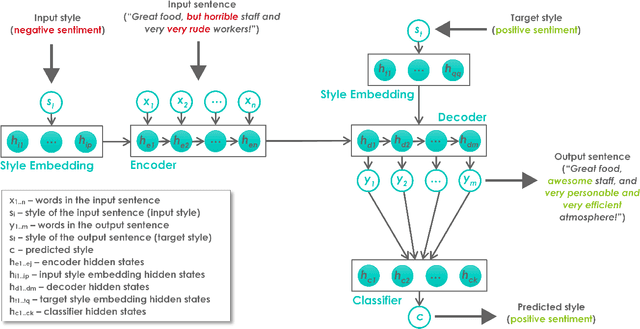
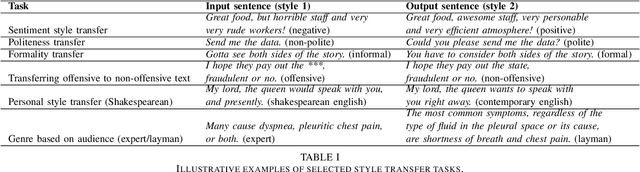

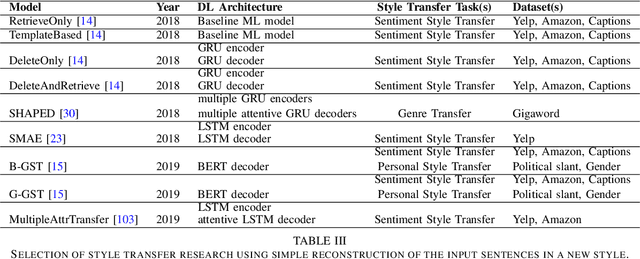
Style is an integral component of a sentence indicated by the choice of words a person makes. Different people have different ways of expressing themselves, however, they adjust their speaking and writing style to a social context, an audience, an interlocutor or the formality of an occasion. Text style transfer is defined as a task of adapting and/or changing the stylistic manner in which a sentence is written, while preserving the meaning of the original sentence. A systematic review of text style transfer methodologies using deep learning is presented in this paper. We point out the technological advances in deep neural networks that have been the driving force behind current successes in the fields of natural language understanding and generation. The review is structured around two key stages in the text style transfer process, namely, representation learning and sentence generation in a new style. The discussion highlights the commonalities and differences between proposed solutions as well as challenges and opportunities that are expected to direct and foster further research in the field.
Recent Advances in SQL Query Generation: A Survey
May 15, 2020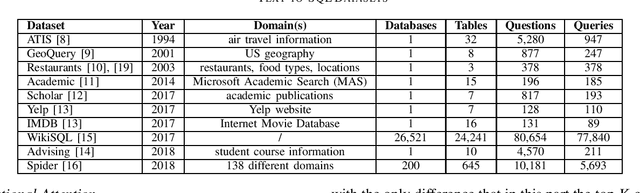
Natural language is hypothetically the best user interface for many domains. However, general models that provide an interface between natural language and any other domain still do not exist. Providing natural language interface to relational databases could possibly attract a vast majority of users that are or are not proficient with query languages. With the rise of deep learning techniques, there is extensive ongoing research in designing a suitable natural language interface to relational databases. This survey aims to overview some of the latest methods and models proposed in the area of SQL query generation from natural language. We describe models with various architectures such as convolutional neural networks, recurrent neural networks, pointer networks, reinforcement learning, etc. Several datasets intended to address the problem of SQL query generation are interpreted and briefly overviewed. In the end, evaluation metrics utilized in the field are presented mainly as a combination of execution accuracy and logical form accuracy.
Comparative Analysis of Word Embeddings for Capturing Word Similarities
May 08, 2020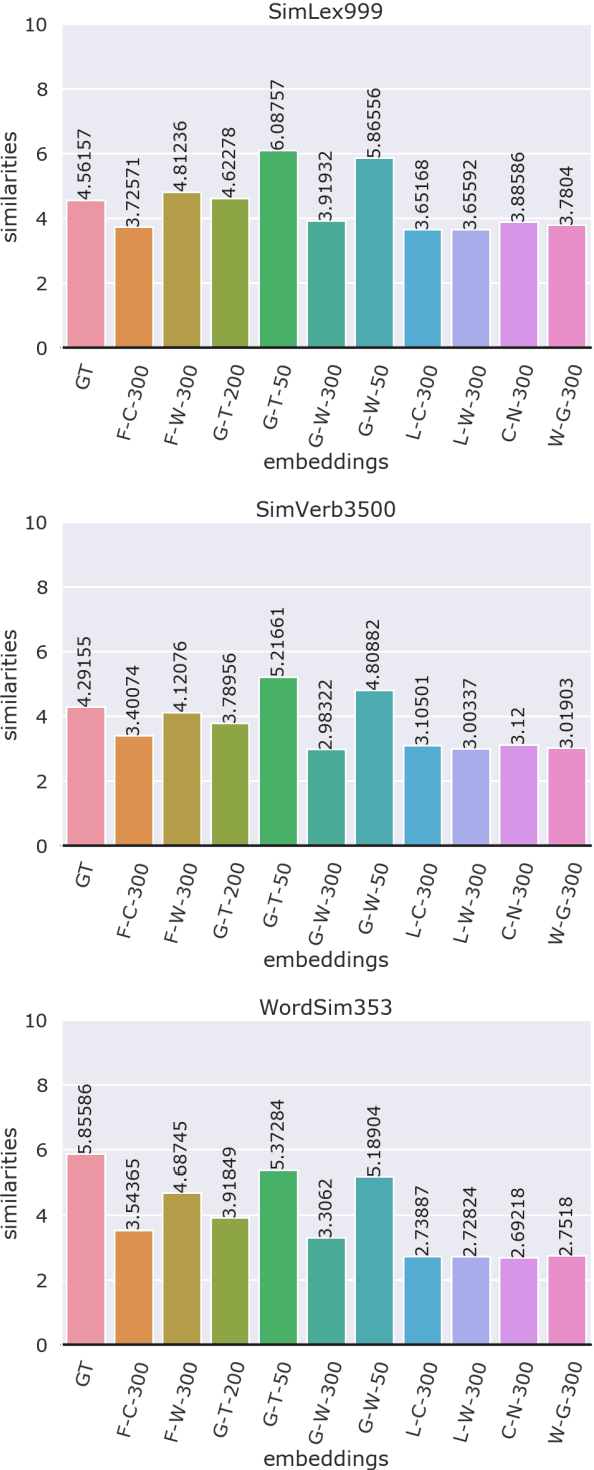

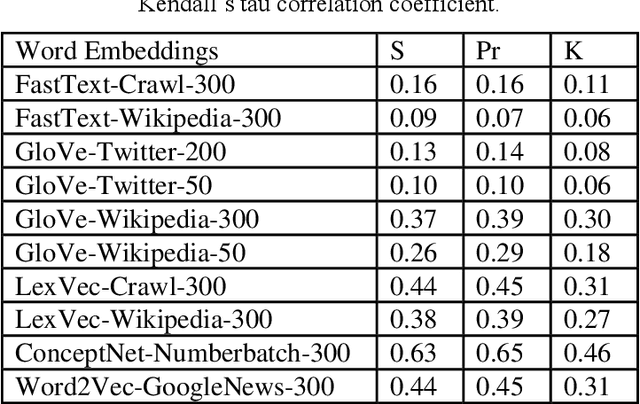
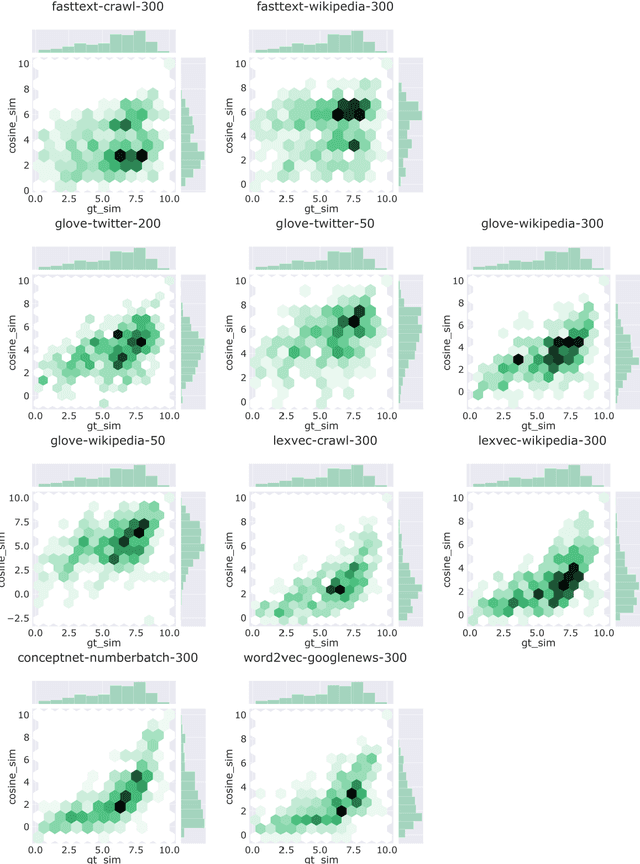
Distributed language representation has become the most widely used technique for language representation in various natural language processing tasks. Most of the natural language processing models that are based on deep learning techniques use already pre-trained distributed word representations, commonly called word embeddings. Determining the most qualitative word embeddings is of crucial importance for such models. However, selecting the appropriate word embeddings is a perplexing task since the projected embedding space is not intuitive to humans. In this paper, we explore different approaches for creating distributed word representations. We perform an intrinsic evaluation of several state-of-the-art word embedding methods. Their performance on capturing word similarities is analysed with existing benchmark datasets for word pairs similarities. The research in this paper conducts a correlation analysis between ground truth word similarities and similarities obtained by different word embedding methods.
* Part of the 6th International Conference on Natural Language Processing (NATP 2020)