 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Word Embeddings for Capturing Word Similarities
Paper and Code
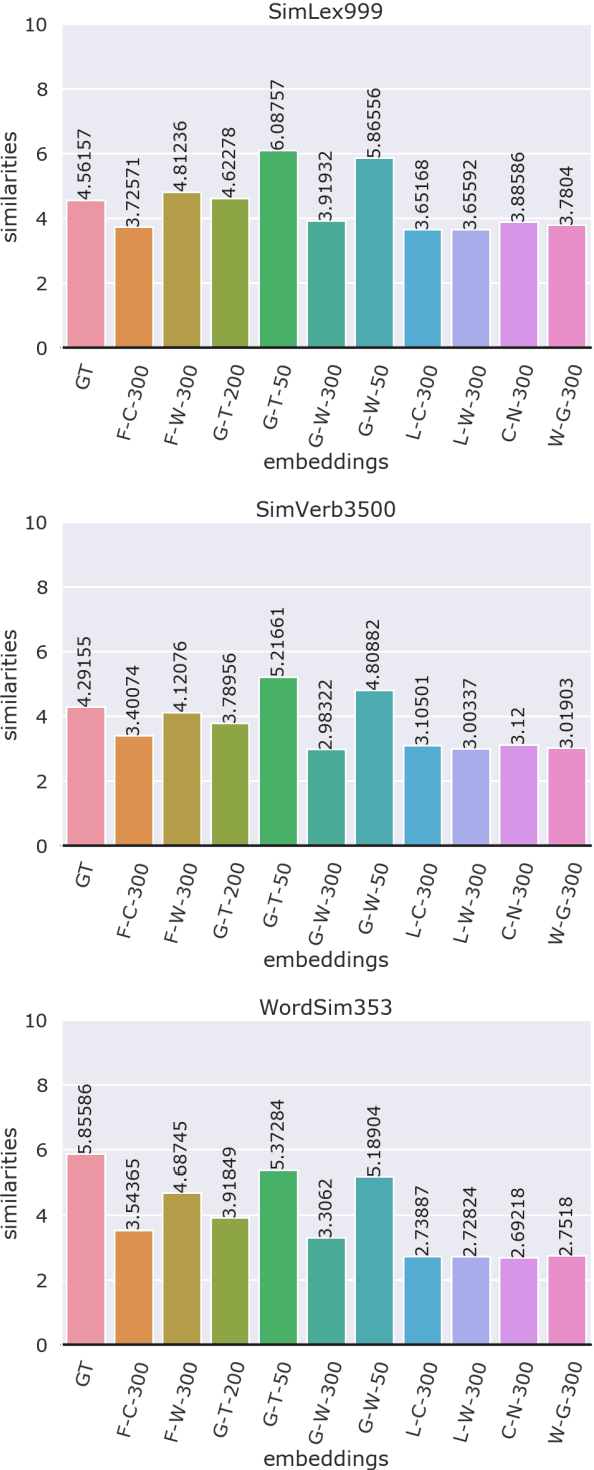

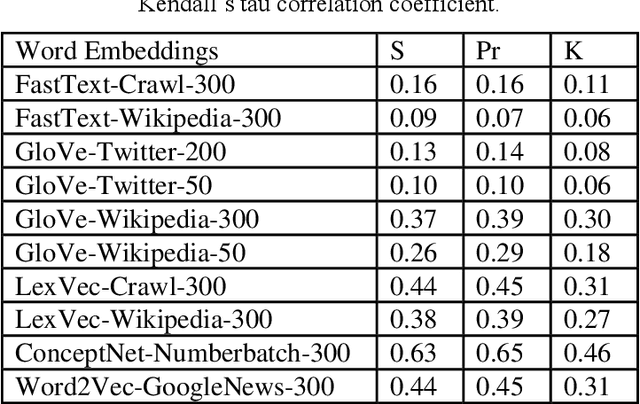
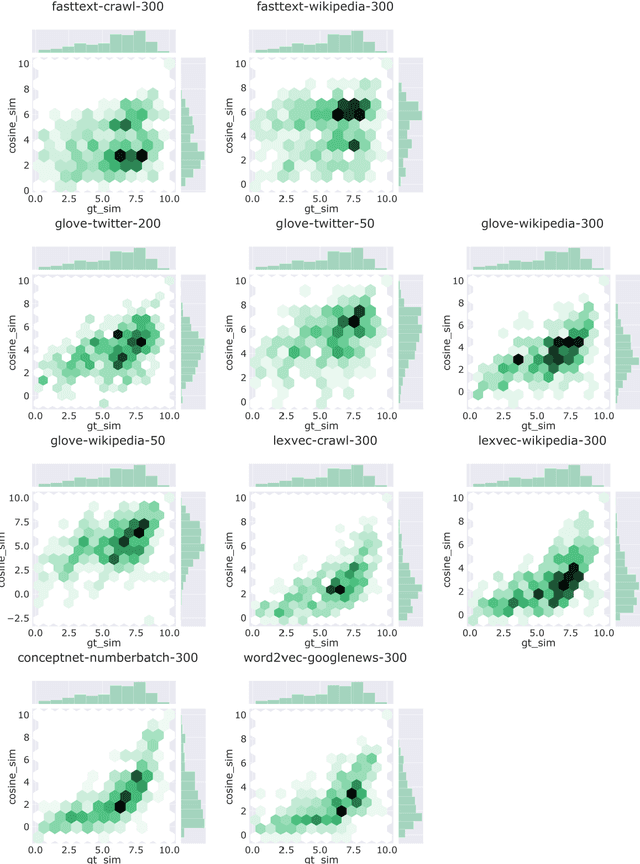
Distributed language representation has become the most widely used technique for language representation in various natural language processing tasks. Most of the natural language processing models that are based on deep learning techniques use already pre-trained distributed word representations, commonly called word embeddings. Determining the most qualitative word embeddings is of crucial importance for such models. However, selecting the appropriate word embeddings is a perplexing task since the projected embedding space is not intuitive to humans. In this paper, we explore different approaches for creating distributed word representations. We perform an intrinsic evaluation of several state-of-the-art word embedding methods. Their performance on capturing word similarities is analysed with existing benchmark datasets for word pairs similarities. The research in this paper conducts a correlation analysis between ground truth word similarities and similarities obtained by different word embedding methods.