 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality and Generalizability: Identifiability and Learning Methods
Oct 04, 2021This PhD thesis contains several contributions to the field of statistical causal modeling. Statistical causal models are statistical models embedded with causal assumptions that allow for the inference and reasoning about the behavior of stochastic systems affected by external manipulation (interventions). This thesis contributes to the research areas concerning the estimation of causal effects, causal structure learning, and distributionally robust (out-of-distribution generalizing) prediction methods. We present novel and consistent linear and non-linear causal effects estimators in instrumental variable settings that employ data-dependent mean squared prediction error regularization. Our proposed estimators show, in certain settings, mean squared error improvements compared to both canonical and state-of-the-art estimators. We show that recent research on distributionally robust prediction methods has connections to well-studied estimators from econometrics. This connection leads us to prove that general K-class estimators possess distributional robustness properties. We, furthermore, propose a general framework for distributional robustness with respect to intervention-induced distributions. In this framework, we derive sufficient conditions for the identifiability of distributionally robust prediction methods and present impossibility results that show the necessity of several of these conditions. We present a new structure learning method applicable in additive noise models with directed trees as causal graphs. We prove consistency in a vanishing identifiability setup and provide a method for testing substructure hypotheses with asymptotic family-wise error control that remains valid post-selection. Finally, we present heuristic ideas for learning summary graphs of nonlinear time-series models.
Structure Learning for Directed Trees
Aug 19, 2021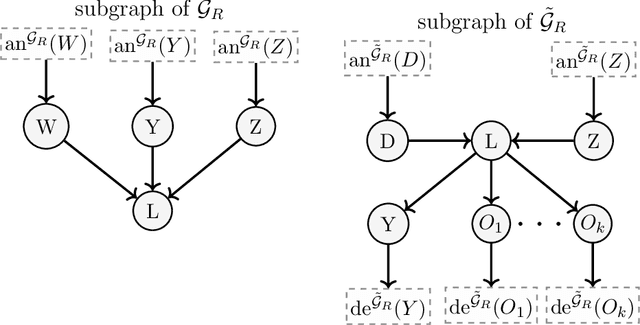
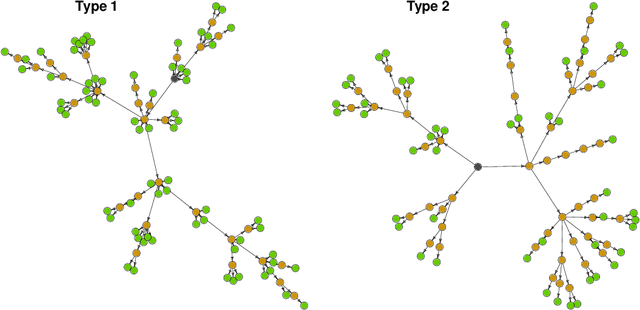


Knowing the causal structure of a system is of fundamental interest in many areas of science and can aid the design of prediction algorithms that work well under manipulations to the system. The causal structure becomes identifiable from the observational distribution under certain restrictions. To learn the structure from data, score-based methods evaluate different graphs according to the quality of their fits. However, for large nonlinear models, these rely on heuristic optimization approaches with no general guarantees of recovering the true causal structure. In this paper, we consider structure learning of directed trees. We propose a fast and scalable method based on Chu-Liu-Edmonds' algorithm we call causal additive trees (CAT). For the case of Gaussian errors, we prove consistency in an asymptotic regime with a vanishing identifiability gap. We also introduce a method for testing substructure hypotheses with asymptotic family-wise error rate control that is valid post-selection and in unidentified settings. Furthermore, we study the identifiability gap, which quantifies how much better the true causal model fits the observational distribution, and prove that it is lower bounded by local properties of the causal model. Simulation studies demonstrate the favorable performance of CAT compared to competing structure learning methods.
Distributional Robustness of K-class Estimators and the PULSE
May 07, 2020
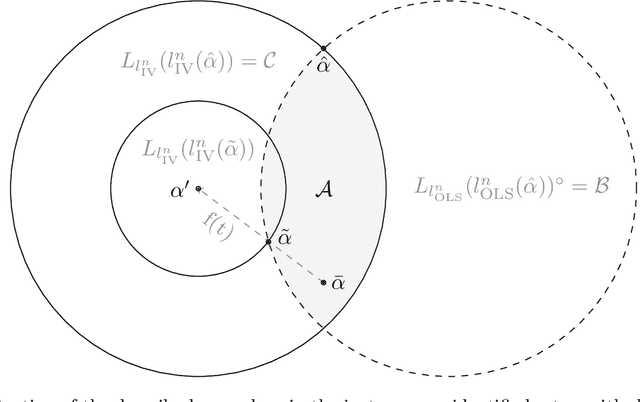
In causal settings, such as instrumental variable settings, it is well known that estimators based on ordinary least squares (OLS) can yield biased and non-consistent estimates of the causal parameters. This is partially overcome by two-stage least squares (TSLS) estimators. These are, under weak assumptions, consistent but do not have desirable finite sample properties: in many models, for example, they do not have finite moments. The set of K-class estimators can be seen as a non-linear interpolation between OLS and TSLS and are known to have improved finite sample properties. Recently, in causal discovery, invariance properties such as the moment criterion which TSLS estimators leverage have been exploited for causal structure learning: e.g., in cases, where the causal parameter is not identifiable, some structure of the non-zero components may be identified, and coverage guarantees are available. Subsequently, anchor regression has been proposed to trade-off invariance and predictability. The resulting estimator is shown to have optimal predictive performance under bounded shift interventions. In this paper, we show that the concepts of anchor regression and K-class estimators are closely related. Establishing this connection comes with two benefits: (1) It enables us to prove robustness properties for existing K-class estimators when considering distributional shifts. And, (2), we propose a novel estimator in instrumental variable settings by minimizing the mean squared prediction error subject to the constraint that the estimator lies in an asymptotically valid confidence region of the causal parameter. We call this estimator PULSE (p-uncorrelated least squares estimator) and show that it can be computed efficiently, even though the underlying optimization problem is non-convex. We further prove that it is consistent.