 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Neural Microcircuits as Building Blocks: Concept and Challenges
Mar 24, 2024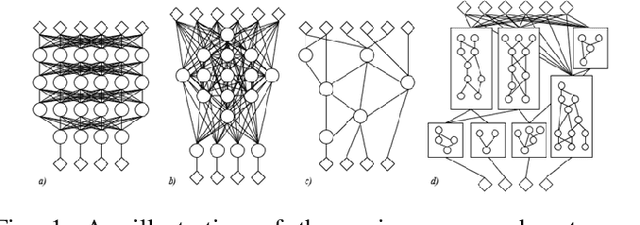
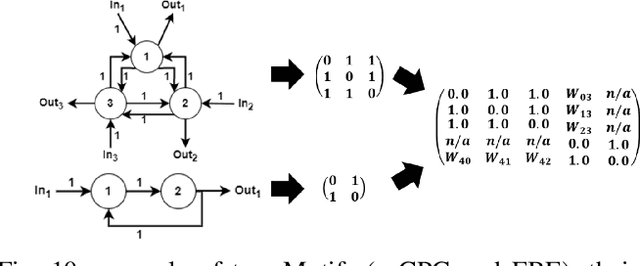
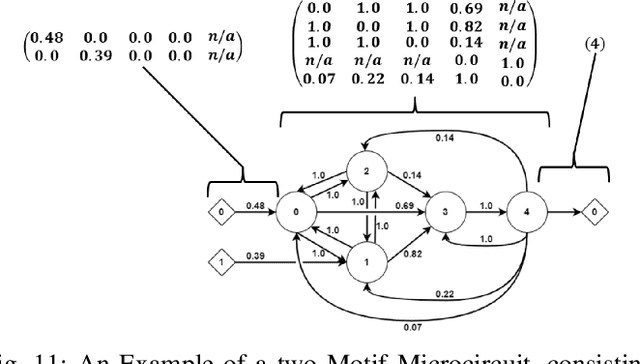
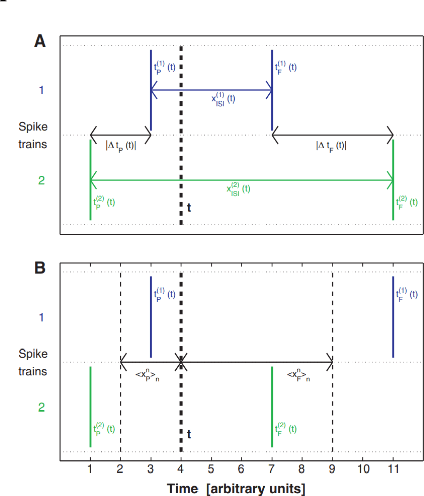
Artificial Neural Networks (ANNs) are one of the most widely employed forms of bio-inspired computation. However the current trend is for ANNs to be structurally homogeneous. Furthermore, this structural homogeneity requires the application of complex training and learning tools that produce application specific ANNs, susceptible to pitfalls such as overfitting. In this paper, an new approach is explored, inspired by the role played in biology by Neural Microcircuits, the so called ``fundamental processing elements'' of organic nervous systems. How large neural networks, particularly Spiking Neural Networks (SNNs) can be assembled using Artificial Neural Microcircuits (ANMs), intended as off-the-shelf components, is articulated; the results of initial work to produce a catalogue of such Microcircuits though the use of Novelty Search is shown; followed by efforts to expand upon this initial work, including a discussion of challenges uncovered during these efforts and explorations of methods by which they might be overcome.
Multi-objective Evolutionary Approach for Efficient Kernel Size and Shape for CNN
Jun 28, 2021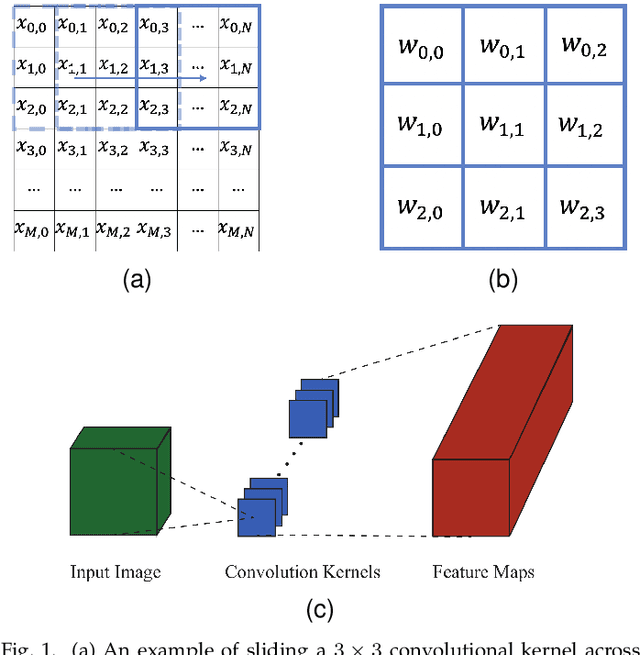
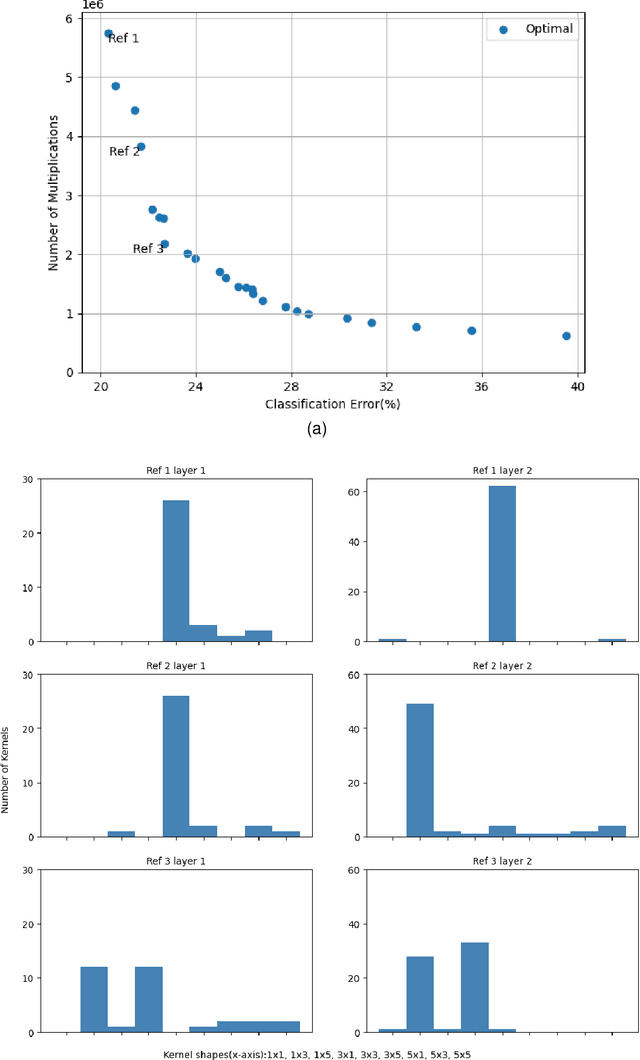
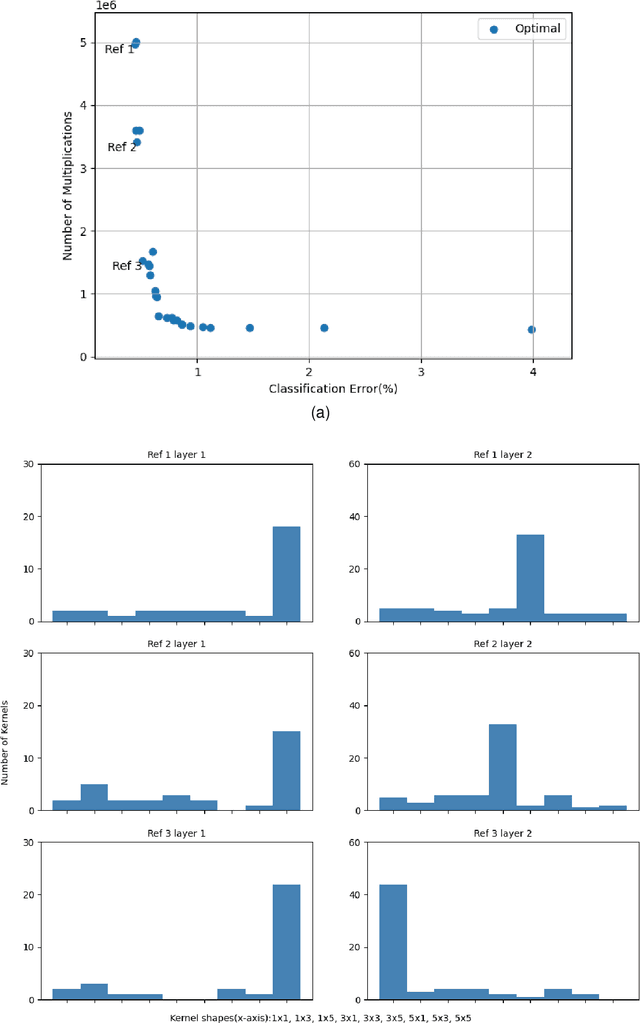

While state-of-the-art development in CNN topology, such as VGGNet and ResNet, have become increasingly accurate, these networks are computationally expensive involving billions of arithmetic operations and parameters. To improve the classification accuracy, state-of-the-art CNNs usually involve large and complex convolutional layers. However, for certain applications, e.g. Internet of Things (IoT), where such CNNs are to be implemented on resource-constrained platforms, the CNN architectures have to be small and efficient. To deal with this problem, reducing the resource consumption in convolutional layers has become one of the most significant solutions. In this work, a multi-objective optimisation approach is proposed to trade-off between the amount of computation and network accuracy by using Multi-Objective Evolutionary Algorithms (MOEAs). The number of convolution kernels and the size of these kernels are proportional to computational resource consumption of CNNs. Therefore, this paper considers optimising the computational resource consumption by reducing the size and number of kernels in convolutional layers. Additionally, the use of unconventional kernel shapes has been investigated and results show these clearly outperform the commonly used square convolution kernels. The main contributions of this paper are therefore a methodology to significantly reduce computational cost of CNNs, based on unconventional kernel shapes, and provide different trade-offs for specific use cases. The experimental results further demonstrate that the proposed method achieves large improvements in resource consumption with no significant reduction in network performance. Compared with the benchmark CNN, the best trade-off architecture shows a reduction in multiplications of up to 6X and with slight increase in classification accuracy on CIFAR-10 dataset.
Multi-objective Optimisation of Digital Circuits based on Cell Mapping in an Industrial EDA Flow
May 21, 2021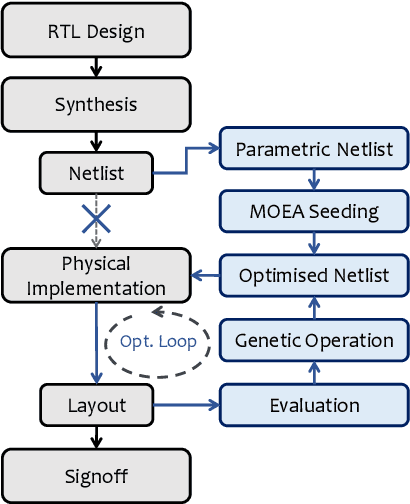
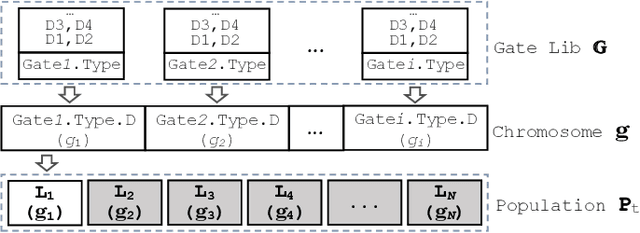
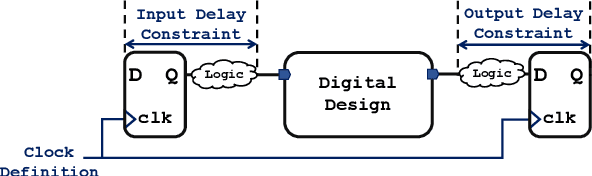
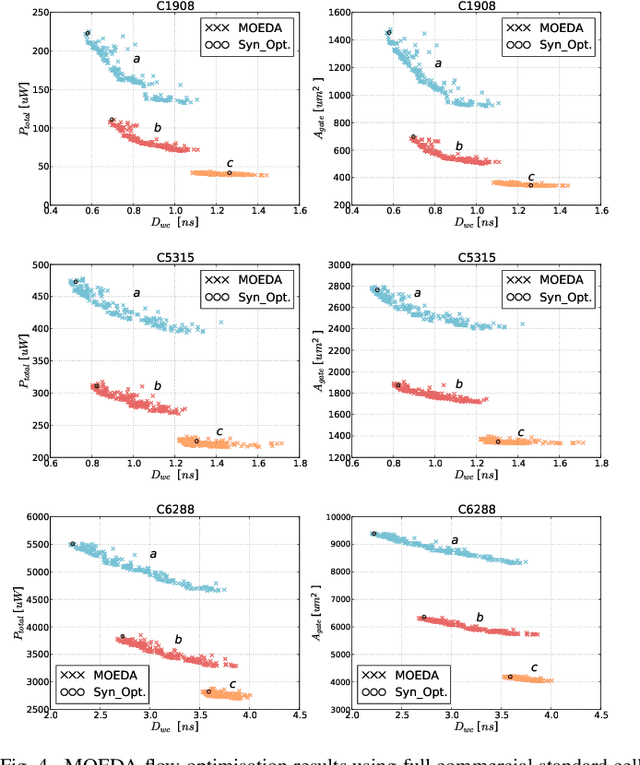
Modern electronic design automation (EDA) tools can handle the complexity of state-of-the-art electronic systems by decomposing them into smaller blocks or cells, introducing different levels of abstraction and staged design flows. However, throughout each independent-optimised design step, overhead and inefficiency can accumulate in the resulting overall design. Performing design-specific optimisation from a more global viewpoint requires more time due to the larger search space, but has the potential to provide solutions with improved performance. In this work, a fully-automated, multi-objective (MO) EDA flow is introduced to address this issue. It specifically tunes drive strength mapping, preceding physical implementation, through multi-objective population-based search algorithms. Designs are evaluated with respect to their power, performance and area (PPA). The proposed approach is capable of expanding the design space, offering a set of Pareto-optimised trade-off solutions for different case-specific utilisation. We have applied the proposed MOEDA framework to ISCAS-85 benchmark circuits using a commercial 65nm standard cell library. The experimental results demonstrate how the MOEDA flow enhances the solutions initially generated by the standard digital flow, and how simultaneously a significant improvement in PPA metrics is achieved.