 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubtractive Modulative Network with Learnable Periodic Activations
Feb 18, 2026We propose the Subtractive Modulative Network (SMN), a novel, parameter-efficient Implicit Neural Representation (INR) architecture inspired by classical subtractive synthesis. The SMN is designed as a principled signal processing pipeline, featuring a learnable periodic activation layer (Oscillator) that generates a multi-frequency basis, and a series of modulative mask modules (Filters) that actively generate high-order harmonics. We provide both theoretical analysis and empirical validation for our design. Our SMN achieves a PSNR of $40+$ dB on two image datasets, comparing favorably against state-of-the-art methods in terms of both reconstruction accuracy and parameter efficiency. Furthermore, consistent advantage is observed on the challenging 3D NeRF novel view synthesis task. Supplementary materials are available at https://inrainbws.github.io/smn/.
* 4 pages, 3 figures, 3 tables
Inter-View Depth Consistency Testing in Depth Difference Subspace
Jan 27, 2023Multiview depth imagery will play a critical role in free-viewpoint television. This technology requires high quality virtual view synthesis to enable viewers to move freely in a dynamic real world scene. Depth imagery at different viewpoints is used to synthesize an arbitrary number of novel views. Usually, depth images at multiple viewpoints are estimated individually by stereo-matching algorithms, and hence, show lack of interview consistency. This inconsistency affects the quality of view synthesis negatively. This paper proposes a method for depth consistency testing in depth difference subspace to enhance the depth representation of a scene across multiple viewpoints. Furthermore, we propose a view synthesis algorithm that uses the obtained consistency information to improve the visual quality of virtual views at arbitrary viewpoints. Our method helps us to find a linear subspace for our depth difference measurements in which we can test the inter-view consistency efficiently. With this, our approach is able to enhance the depth information for real world scenes. In combination with our consistency-adaptive view synthesis, we improve the visual experience of the free-viewpoint user. The experiments show that our approach enhances the objective quality of virtual views by up to 1.4 dB. The advantage for the subjective quality is also demonstrated.
Conditional Mutual information-based Contrastive Loss for Financial Time Series Forecasting
Feb 18, 2020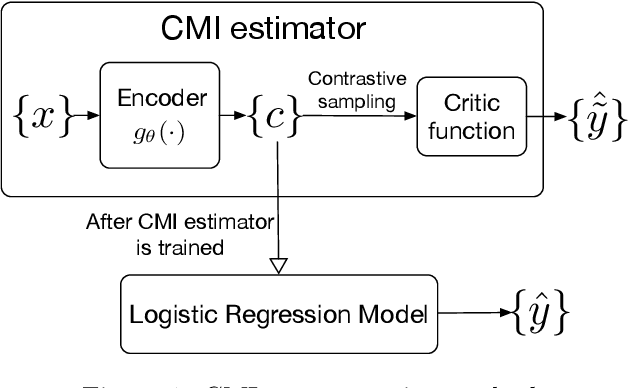



We present a method for financial time series forecasting using representation learning techniques. Recent progress on deep autoregressive models has shown their ability to capture long-term dependencies of the sequence data. However, the shortage of available financial data for training will make the deep models susceptible to the overfitting problem. In this paper, we propose a neural-network-powered conditional mutual information (CMI) estimator for learning representations for the forecasting task. Specifically, we first train an encoder to maximize the mutual information between the latent variables and the label information conditioned on the encoded observed variables. Then the features extracted from the trained encoder are used to learn a subsequent logistic regression model for predicting time series movements. Our proposed estimator transforms the CMI maximization problem to a classification problem whether two encoded representations are sampled from the same class or not. This is equivalent to perform pairwise comparisons of the training datapoints, and thus, improves the generalization ability of the deep autoregressive model. Empirical experiments indicate that our proposed method has the potential to advance the state-of-the-art performance.
Quantization-Based Regularization for Autoencoders
May 27, 2019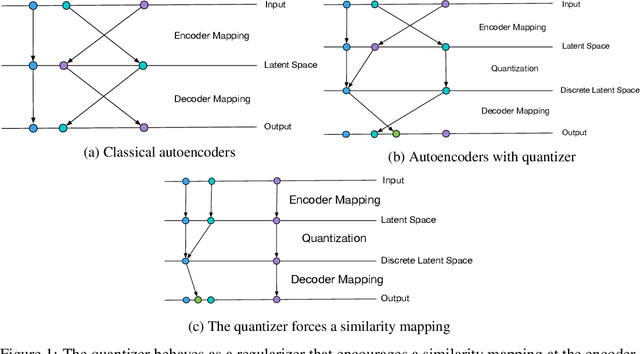


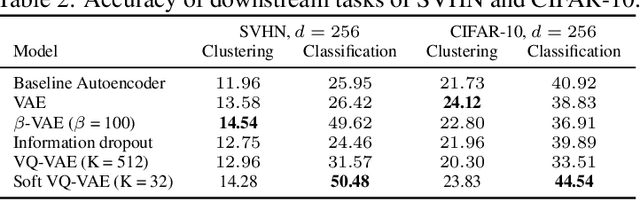
Autoencoders and their variations provide unsupervised models for learning low-dimensional representations for downstream tasks. Without proper regularization, autoencoder models are susceptible to the overfitting problem and the so-called posterior collapse phenomenon. In this paper, we introduce a quantization-based regularizer in the bottleneck stage of autoencoder models to learn meaningful latent representations. We combine both perspectives of Vector Quantized-Variational AutoEncoders (VQ-VAE) and classical denoising regularization schemes of neural networks. We interpret quantizers as regularizers that constrain latent representations while fostering a similarity mapping at the encoder. Before quantization, we impose noise on the latent variables and use a Bayesian estimator to optimize the quantizer-based representation. The introduced bottleneck Bayesian estimator outputs the posterior mean of the centroids to the decoder, and thus, is performing soft quantization of the latent variables. We show that our proposed regularization method results in improved latent representations for both supervised learning and clustering downstream tasks when compared to autoencoders using other bottleneck structures.
Variational Information Bottleneck on Vector Quantized Autoencoders
Aug 02, 2018In this paper, we provide an information-theoretic interpretation of the Vector Quantized-Variational Autoencoder (VQ-VAE). We show that the loss function of the original VQ-VAE can be derived from the variational deterministic information bottleneck (VDIB) principle. On the other hand, the VQ-VAE trained by the Expectation Maximization (EM) algorithm can be viewed as an approximation to the variational information bottleneck(VIB) principle.
Learning Product Codebooks using Vector Quantized Autoencoders for Image Retrieval
Jul 19, 2018


The Vector Quantized-Variational Autoencoder (VQ-VAE) [1] provides an unsupervised model for learning discrete representations by combining vector quantization and autoencoders. The VQ-VAE can avoid the issue of "posterior collapse" so that its learned discrete representation is meaningful. In this paper, we incorporate the product quantization into the bottleneck stage of VQ-VAE and propose an end-to-end unsupervised learning model for the image retrieval tasks. Compared to the classic vector quantization, product quantization has the advantage of generating large size codebook and fast retrieval can be achieved by using the lookup tables that store the distance between every two sub-codewords. In our proposed model, the product codebook is jointly learned with the encoders and decoders of the autoencoders. The encodings of query and database images can be generated by feeding the images into the trained encoder and learned product codebook. The experiment shows that our proposed model outperforms other state-of-the-art hashing and quantization methods for the image retrieval task.