 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFraming Human-Robot Task Communication as a POMDP
Apr 01, 2012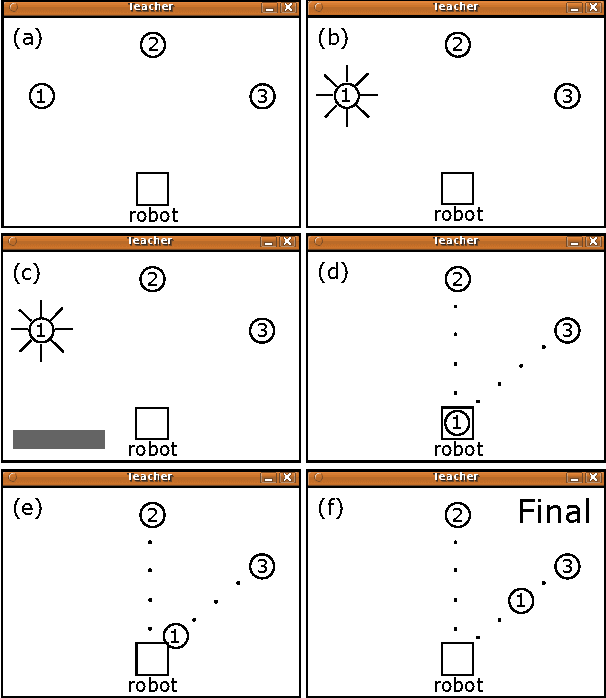
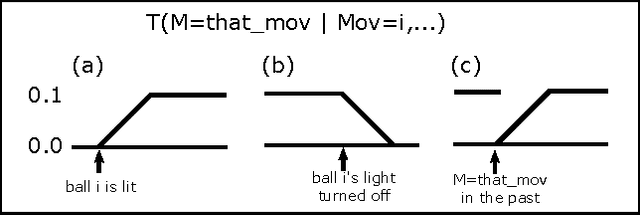
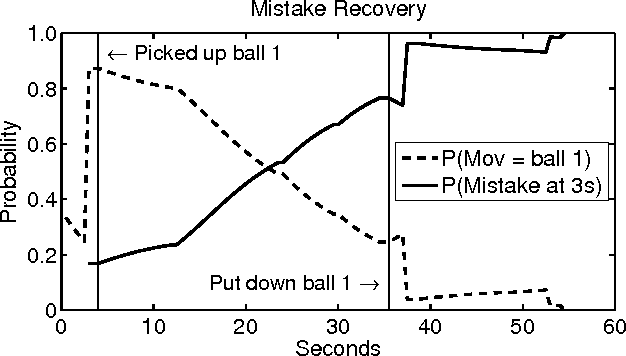
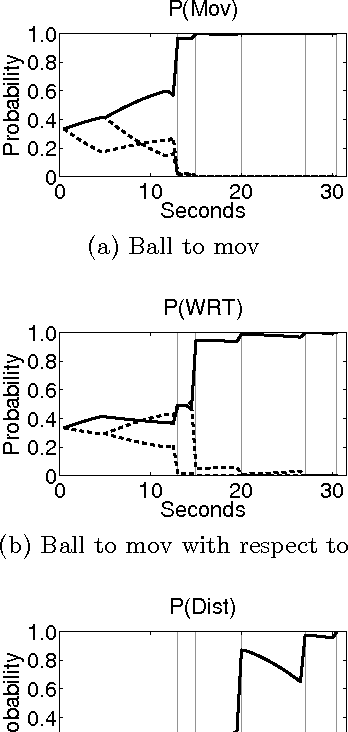
As general purpose robots become more capable, pre-programming of all tasks at the factory will become less practical. We would like for non-technical human owners to be able to communicate, through interaction with their robot, the details of a new task; we call this interaction "task communication". During task communication the robot must infer the details of the task from unstructured human signals and it must choose actions that facilitate this inference. In this paper we propose the use of a partially observable Markov decision process (POMDP) for representing the task communication problem; with the unobservable task details and unobservable intentions of the human teacher captured in the state, with all signals from the human represented as observations, and with the cost function chosen to penalize uncertainty. We work through an example representation of task communication as a POMDP, and present results from a user experiment on an interactive virtual robot, compared with a human controlled virtual robot, for a task involving a single object movement and binary approval input from the teacher. The results suggest that the proposed POMDP representation produces robots that are robust to teacher error, that can accurately infer task details, and that are perceived to be intelligent.
Learning from Humans as an I-POMDP
Apr 01, 2012The interactive partially observable Markov decision process (I-POMDP) is a recently developed framework which extends the POMDP to the multi-agent setting by including agent models in the state space. This paper argues for formulating the problem of an agent learning interactively from a human teacher as an I-POMDP, where the agent \emph{programming} to be learned is captured by random variables in the agent's state space, all \emph{signals} from the human teacher are treated as observed random variables, and the human teacher, modeled as a distinct agent, is explicitly represented in the agent's state space. The main benefits of this approach are: i. a principled action selection mechanism, ii. a principled belief update mechanism, iii. support for the most common teacher \emph{signals}, and iv. the anticipated production of complex beneficial interactions. The proposed formulation, its benefits, and several open questions are presented.