 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorized and performance-portable Quicksort
May 12, 2022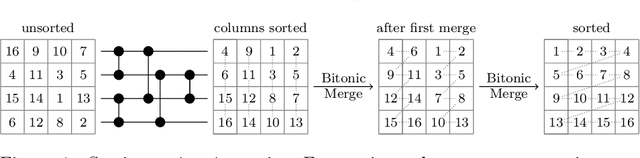

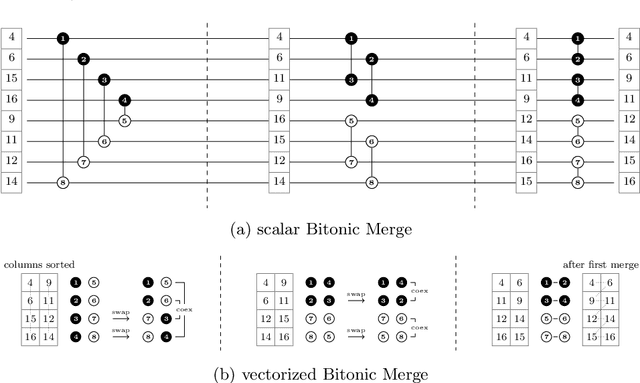

Recent works showed that implementations of Quicksort using vector CPU instructions can outperform the non-vectorized algorithms in widespread use. However, these implementations are typically single-threaded, implemented for a particular instruction set, and restricted to a small set of key types. We lift these three restrictions: our proposed 'vqsort' algorithm integrates into the state-of-the-art parallel sorter 'ips4o', with a geometric mean speedup of 1.59. The same implementation works on seven instruction sets (including SVE and RISC-V V) across four platforms. It also supports floating-point and 16-128 bit integer keys. To the best of our knowledge, this is the fastest sort for non-tuple keys on CPUs, up to 20 times as fast as the sorting algorithms implemented in standard libraries. This paper focuses on the practical engineering aspects enabling the speed and portability, which we have not yet seen demonstrated for a Quicksort implementation. Furthermore, we introduce compact and transpose-free sorting networks for in-register sorting of small arrays, and a vector-friendly pivot sampling strategy that is robust against adversarial input.
Optimization for Classical Machine Learning Problems on the GPU
Mar 30, 2022
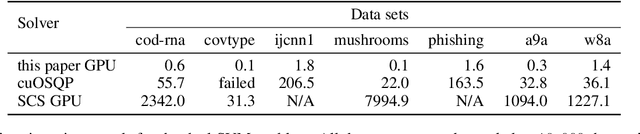
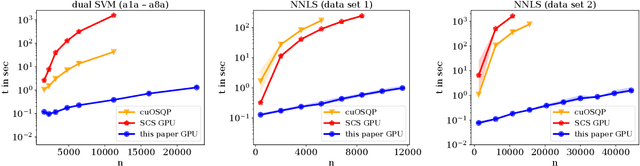

Constrained optimization problems arise frequently in classical machine learning. There exist frameworks addressing constrained optimization, for instance, CVXPY and GENO. However, in contrast to deep learning frameworks, GPU support is limited. Here, we extend the GENO framework to also solve constrained optimization problems on the GPU. The framework allows the user to specify constrained optimization problems in an easy-to-read modeling language. A solver is then automatically generated from this specification. When run on the GPU, the solver outperforms state-of-the-art approaches like CVXPY combined with a GPU-accelerated solver such as cuOSQP or SCS by a few orders of magnitude.