 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Look at the Applicability of Markov Logic Networks for Music Signal Analysis
Jan 16, 2020
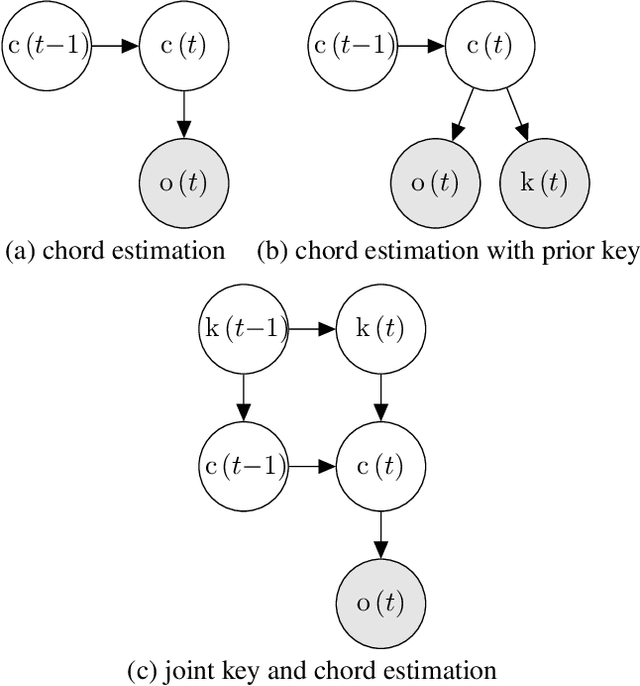
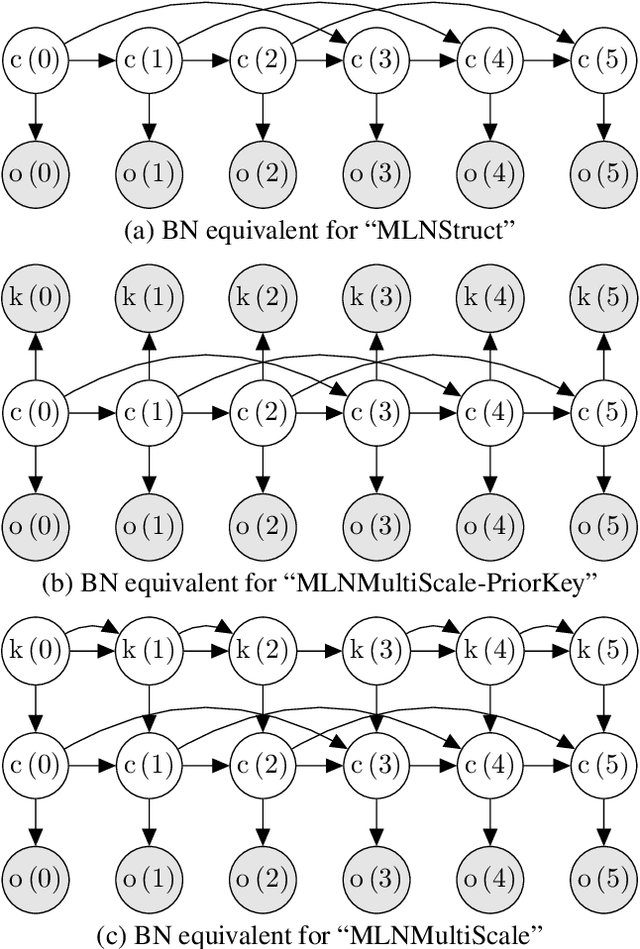
In recent years, Markov logic networks (MLNs) have been proposed as a potentially useful paradigm for music signal analysis. Because all hidden Markov models can be reformulated as MLNs, the latter can provide an all-encompassing framework that reuses and extends previous work in the field. However, just because it is theoretically possible to reformulate previous work as MLNs, does not mean that it is advantageous. In this paper, we analyse some proposed examples of MLNs for musical analysis and consider their practical disadvantages when compared to formulating the same musical dependence relationships as (dynamic) Bayesian networks. We argue that a number of practical hurdles such as the lack of support for sequences and for arbitrary continuous probability distributions make MLNs less than ideal for the proposed musical applications, both in terms of easy of formulation and computational requirements due to their required inference algorithms. These conclusions are not specific to music, but apply to other fields as well, especially when sequential data with continuous observations is involved. Finally, we show that the ideas underlying the proposed examples can be expressed perfectly well in the more commonly used framework of (dynamic) Bayesian networks.
An Augmented Lagrangian Method for Piano Transcription using Equal Loudness Thresholding and LSTM-based Decoding
Jul 30, 2017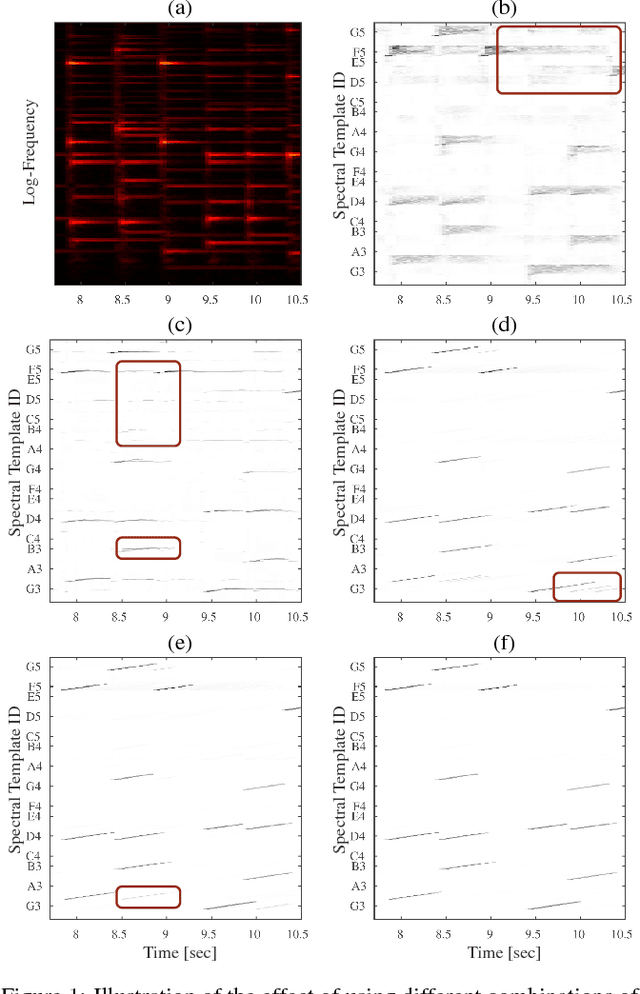
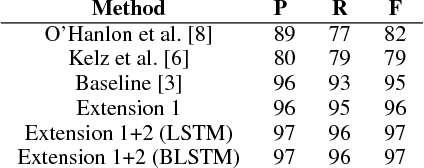
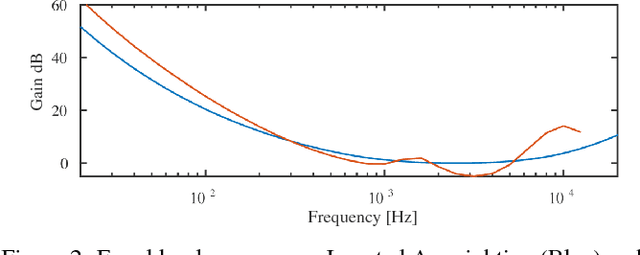
A central goal in automatic music transcription is to detect individual note events in music recordings. An important variant is instrument-dependent music transcription where methods can use calibration data for the instruments in use. However, despite the additional information, results rarely exceed an f-measure of 80%. As a potential explanation, the transcription problem can be shown to be badly conditioned and thus relies on appropriate regularization. A recently proposed method employs a mixture of simple, convex regularizers (to stabilize the parameter estimation process) and more complex terms (to encourage more meaningful structure). In this paper, we present two extensions to this method. First, we integrate a computational loudness model to better differentiate real from spurious note detections. Second, we employ (Bidirectional) Long Short Term Memory networks to re-weight the likelihood of detected note constellations. Despite their simplicity, our two extensions lead to a drop of about 35% in note error rate compared to the state-of-the-art.
Structured Dropout for Weak Label and Multi-Instance Learning and Its Application to Score-Informed Source Separation
Dec 26, 2016
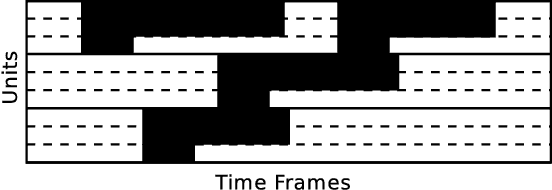

Many success stories involving deep neural networks are instances of supervised learning, where available labels power gradient-based learning methods. Creating such labels, however, can be expensive and thus there is increasing interest in weak labels which only provide coarse information, with uncertainty regarding time, location or value. Using such labels often leads to considerable challenges for the learning process. Current methods for weak-label training often employ standard supervised approaches that additionally reassign or prune labels during the learning process. The information gain, however, is often limited as only the importance of labels where the network already yields reasonable results is boosted. We propose treating weak-label training as an unsupervised problem and use the labels to guide the representation learning to induce structure. To this end, we propose two autoencoder extensions: class activity penalties and structured dropout. We demonstrate the capabilities of our approach in the context of score-informed source separation of music.