 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGalerkin Neural Networks: A Framework for Approximating Variational Equations with Error Control
May 28, 2021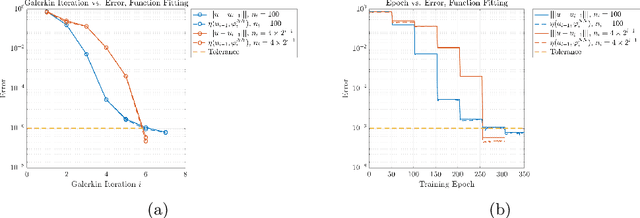
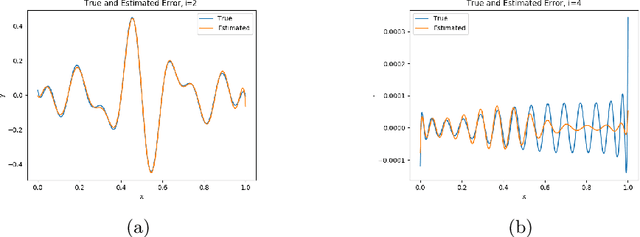
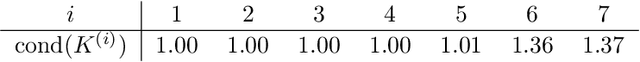
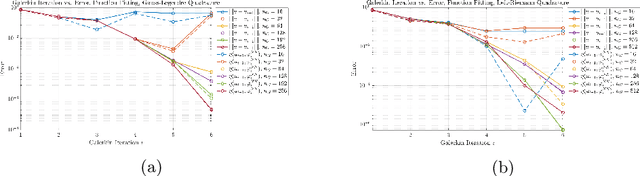
We present a new approach to using neural networks to approximate the solutions of variational equations, based on the adaptive construction of a sequence of finite-dimensional subspaces whose basis functions are realizations of a sequence of neural networks. The finite-dimensional subspaces are then used to define a standard Galerkin approximation of the variational equation. This approach enjoys a number of advantages, including: the sequential nature of the algorithm offers a systematic approach to enhancing the accuracy of a given approximation; the sequential enhancements provide a useful indicator for the error that can be used as a criterion for terminating the sequential updates; the basic approach is largely oblivious to the nature of the partial differential equation under consideration; and, some basic theoretical results are presented regarding the convergence (or otherwise) of the method which are used to formulate basic guidelines for applying the method.
Plateau Phenomenon in Gradient Descent Training of ReLU networks: Explanation, Quantification and Avoidance
Jul 14, 2020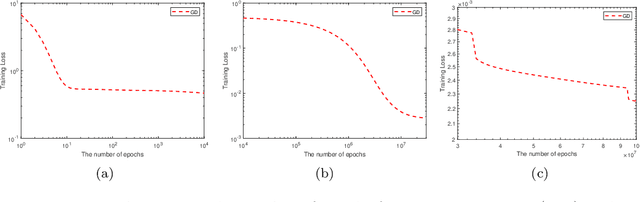
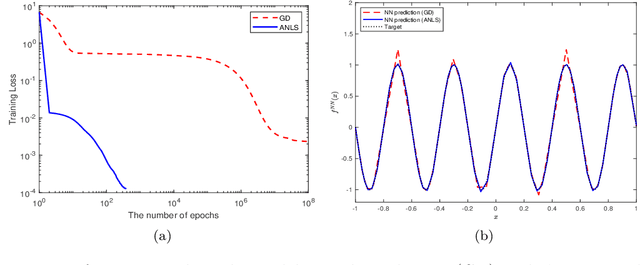
The ability of neural networks to provide `best in class' approximation across a wide range of applications is well-documented. Nevertheless, the powerful expressivity of neural networks comes to naught if one is unable to effectively train (choose) the parameters defining the network. In general, neural networks are trained by gradient descent type optimization methods, or a stochastic variant thereof. In practice, such methods result in the loss function decreases rapidly at the beginning of training but then, after a relatively small number of steps, significantly slow down. The loss may even appear to stagnate over the period of a large number of epochs, only to then suddenly start to decrease fast again for no apparent reason. This so-called plateau phenomenon manifests itself in many learning tasks. The present work aims to identify and quantify the root causes of plateau phenomenon. No assumptions are made on the number of neurons relative to the number of training data, and our results hold for both the lazy and adaptive regimes. The main findings are: plateaux correspond to periods during which activation patterns remain constant, where activation pattern refers to the number of data points that activate a given neuron; quantification of convergence of the gradient flow dynamics; and, characterization of stationary points in terms solutions of local least squares regression lines over subsets of the training data. Based on these conclusions, we propose a new iterative training method, the Active Neuron Least Squares (ANLS), characterised by the explicit adjustment of the activation pattern at each step, which is designed to enable a quick exit from a plateau. Illustrative numerical examples are included throughout.