 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChiNet: Deep Recurrent Convolutional Learning for Multimodal Spacecraft Pose Estimation
Aug 23, 2021


This paper presents an innovative deep learning pipeline which estimates the relative pose of a spacecraft by incorporating the temporal information from a rendezvous sequence. It leverages the performance of long short-term memory (LSTM) units in modelling sequences of data for the processing of features extracted by a convolutional neural network (CNN) backbone. Three distinct training strategies, which follow a coarse-to-fine funnelled approach, are combined to facilitate feature learning and improve end-to-end pose estimation by regression. The capability of CNNs to autonomously ascertain feature representations from images is exploited to fuse thermal infrared data with red-green-blue (RGB) inputs, thus mitigating the effects of artefacts from imaging space objects in the visible wavelength. Each contribution of the proposed framework, dubbed ChiNet, is demonstrated on a synthetic dataset, and the complete pipeline is validated on experimental data.
Robust On-Manifold Optimization for Uncooperative Space Relative Navigation with a Single Camera
May 14, 2020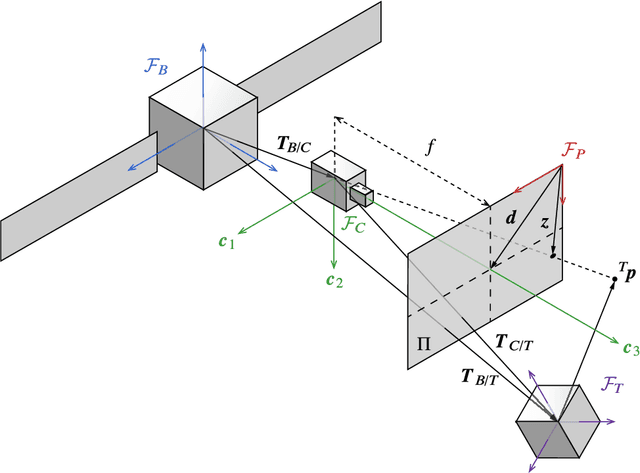
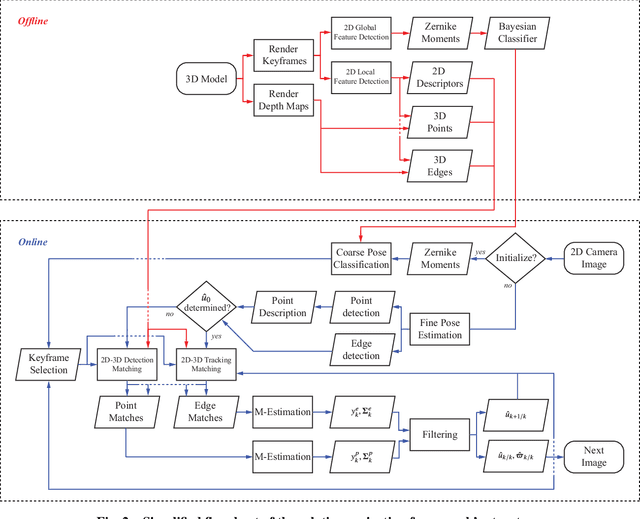
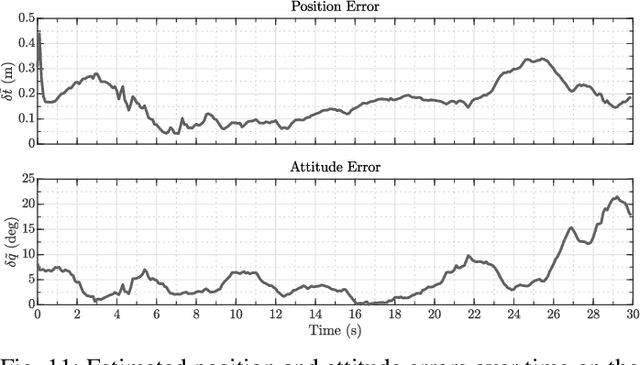
Optical cameras are gaining popularity as the suitable sensor for relative navigation in space due to their attractive sizing, power and cost properties when compared to conventional flight hardware or costly laser-based systems. However, a camera cannot infer depth information on its own, which is often solved by introducing complementary sensors or a second camera. In this paper, an innovative model-based approach is instead demonstrated to estimate the six-dimensional pose of a target object relative to the chaser spacecraft using solely a monocular setup. The observed facet of the target is tackled as a classification problem, where the three-dimensional shape is learned offline using Gaussian mixture modeling. The estimate is refined by minimizing two different robust loss functions based on local feature correspondences. The resulting pseudo-measurements are then processed and fused with an extended Kalman filter. The entire optimization framework is designed to operate directly on the $SE\text{(3)}$ manifold, uncoupling the process and measurement models from the global attitude state representation. It is validated on realistic synthetic and laboratory datasets of a rendezvous trajectory with the complex spacecraft Envisat. It is demonstrated how it achieves an estimate of the relative pose with high accuracy over its full tumbling motion.
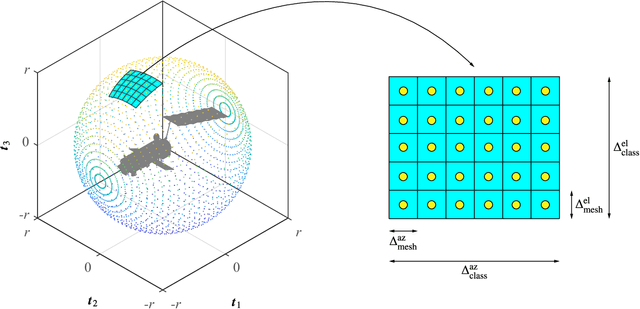
Single and Cross-Dimensional Feature Detection and Description: An Evaluation
Oct 18, 2019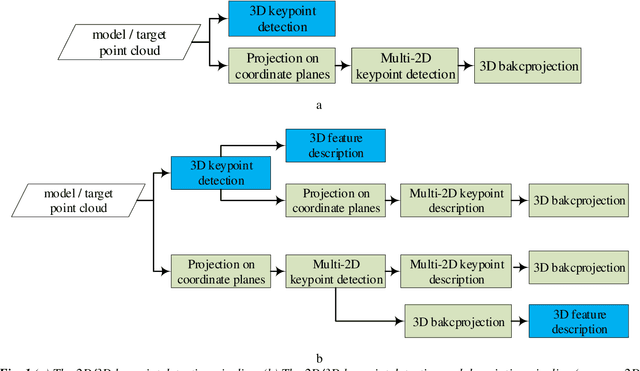
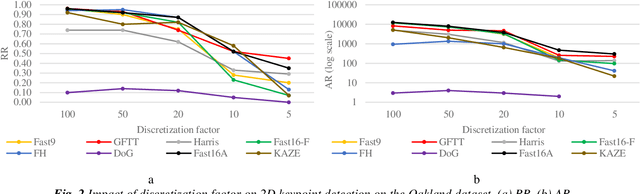

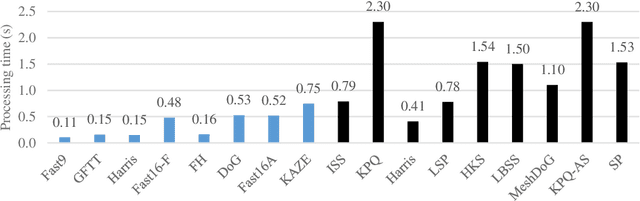
Three-dimensional local feature detection and description techniques are widely used for object registration and recognition applications. Although several evaluations of 3D local feature detection and description methods have already been published, these are constrained in a single dimensional scheme, i.e. either 3D or 2D methods that are applied onto multiple projections of the 3D data. However, cross-dimensional (mixed 2D and 3D) feature detection and description has yet to be investigated. Here, we evaluated the performance of both single and cross-dimensional feature detection and description methods on several 3D datasets and demonstrated the superiority of cross-dimensional over single-dimensional schemes.