 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEIE: Efficient Inference Engine on Compressed Deep Neural Network
May 03, 2016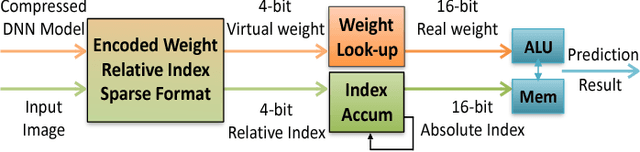
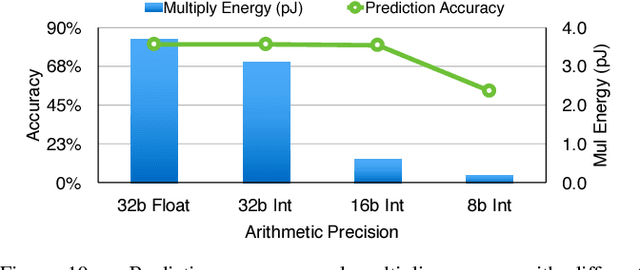


State-of-the-art deep neural networks (DNNs) have hundreds of millions of connections and are both computationally and memory intensive, making them difficult to deploy on embedded systems with limited hardware resources and power budgets. While custom hardware helps the computation, fetching weights from DRAM is two orders of magnitude more expensive than ALU operations, and dominates the required power. Previously proposed 'Deep Compression' makes it possible to fit large DNNs (AlexNet and VGGNet) fully in on-chip SRAM. This compression is achieved by pruning the redundant connections and having multiple connections share the same weight. We propose an energy efficient inference engine (EIE) that performs inference on this compressed network model and accelerates the resulting sparse matrix-vector multiplication with weight sharing. Going from DRAM to SRAM gives EIE 120x energy saving; Exploiting sparsity saves 10x; Weight sharing gives 8x; Skipping zero activations from ReLU saves another 3x. Evaluated on nine DNN benchmarks, EIE is 189x and 13x faster when compared to CPU and GPU implementations of the same DNN without compression. EIE has a processing power of 102GOPS/s working directly on a compressed network, corresponding to 3TOPS/s on an uncompressed network, and processes FC layers of AlexNet at 1.88x10^4 frames/sec with a power dissipation of only 600mW. It is 24,000x and 3,400x more energy efficient than a CPU and GPU respectively. Compared with DaDianNao, EIE has 2.9x, 19x and 3x better throughput, energy efficiency and area efficiency.