 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE3D: A Framework For Saliency Method Evaluation In 3D Imaging
May 23, 2024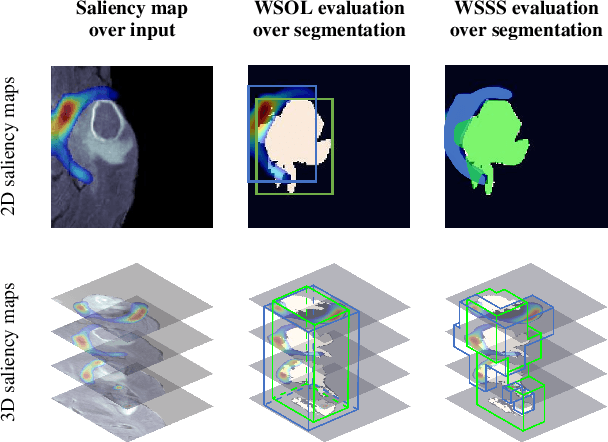
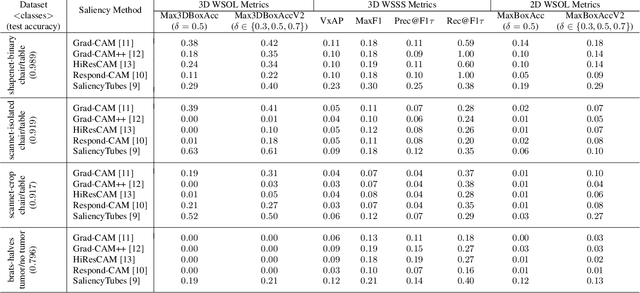


For more than a decade, deep learning models have been dominating in various 2D imaging tasks. Their application is now extending to 3D imaging, with 3D Convolutional Neural Networks (3D CNNs) being able to process LIDAR, MRI, and CT scans, with significant implications for fields such as autonomous driving and medical imaging. In these critical settings, explaining the model's decisions is fundamental. Despite recent advances in Explainable Artificial Intelligence, however, little effort has been devoted to explaining 3D CNNs, and many works explain these models via inadequate extensions of 2D saliency methods. One fundamental limitation to the development of 3D saliency methods is the lack of a benchmark to quantitatively assess them on 3D data. To address this issue, we propose SE3D: a framework for Saliency method Evaluation in 3D imaging. We propose modifications to ShapeNet, ScanNet, and BraTS datasets, and evaluation metrics to assess saliency methods for 3D CNNs. We evaluate both state-of-the-art saliency methods designed for 3D data and extensions of popular 2D saliency methods to 3D. Our experiments show that 3D saliency methods do not provide explanations of sufficient quality, and that there is margin for future improvements and safer applications of 3D CNNs in critical fields.