 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Target-Side Morphology in Neural Machine Translation: A Comparison of Strategies
Mar 25, 2022


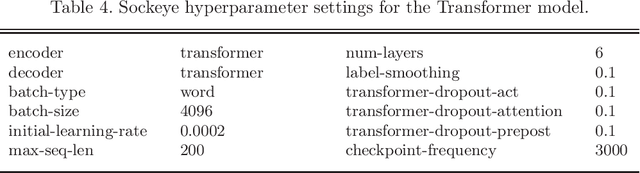
Morphologically rich languages pose difficulties to machine translation. Machine translation engines that rely on statistical learning from parallel training data, such as state-of-the-art neural systems, face challenges especially with rich morphology on the output language side. Key challenges of rich target-side morphology in data-driven machine translation include: (1) A large amount of differently inflected word surface forms entails a larger vocabulary and thus data sparsity. (2) Some inflected forms of infrequent terms typically do not appear in the training corpus, which makes closed-vocabulary systems unable to generate these unobserved variants. (3) Linguistic agreement requires the system to correctly match the grammatical categories between inflected word forms in the output sentence, both in terms of target-side morpho-syntactic wellformedness and semantic adequacy with respect to the input. In this paper, we re-investigate two target-side linguistic processing techniques: a lemma-tag strategy and a linguistically informed word segmentation strategy. Our experiments are conducted on a English-German translation task under three training corpus conditions of different magnitudes. We find that a stronger Transformer baseline leaves less room for improvement than a shallow-RNN encoder-decoder model when translating in-domain. However, we find that linguistic modeling of target-side morphology does benefit the Transformer model when the same system is applied to out-of-domain input text. We also successfully apply our approach to English to Czech translation.
Modeling Target-Side Inflection in Neural Machine Translation
Sep 05, 2017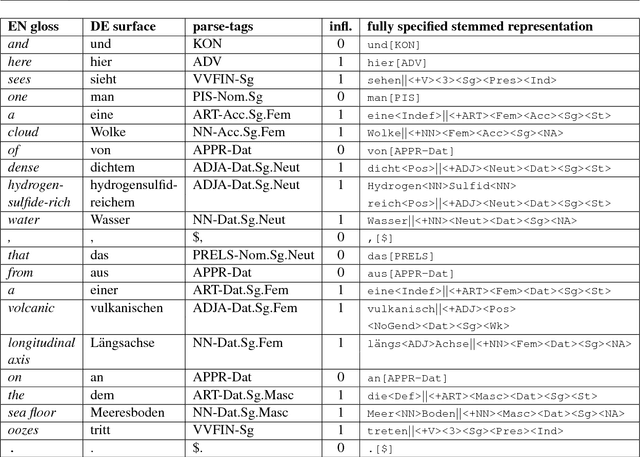


NMT systems have problems with large vocabulary sizes. Byte-pair encoding (BPE) is a popular approach to solving this problem, but while BPE allows the system to generate any target-side word, it does not enable effective generalization over the rich vocabulary in morphologically rich languages with strong inflectional phenomena. We introduce a simple approach to overcome this problem by training a system to produce the lemma of a word and its morphologically rich POS tag, which is then followed by a deterministic generation step. We apply this strategy for English-Czech and English-German translation scenarios, obtaining improvements in both settings. We furthermore show that the improvement is not due to only adding explicit morphological information.