 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Target-Side Inflection in Neural Machine Translation
Paper and Code
Sep 05, 2017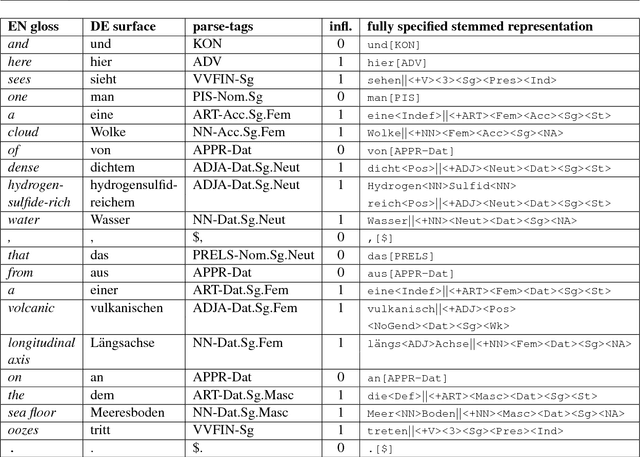
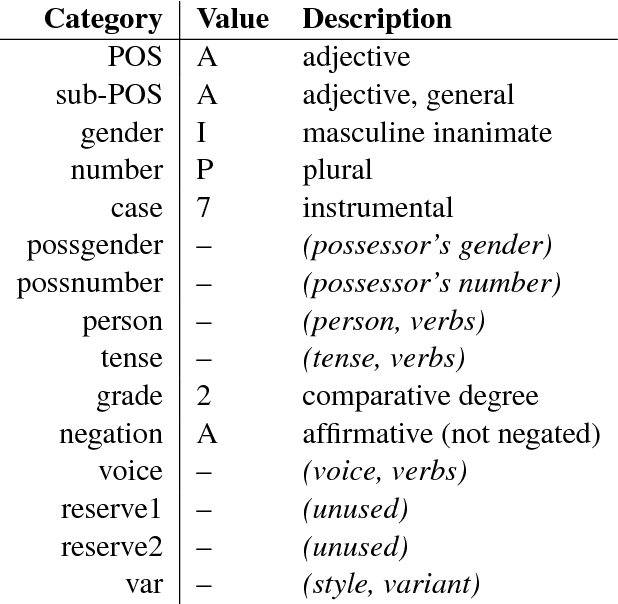


NMT systems have problems with large vocabulary sizes. Byte-pair encoding (BPE) is a popular approach to solving this problem, but while BPE allows the system to generate any target-side word, it does not enable effective generalization over the rich vocabulary in morphologically rich languages with strong inflectional phenomena. We introduce a simple approach to overcome this problem by training a system to produce the lemma of a word and its morphologically rich POS tag, which is then followed by a deterministic generation step. We apply this strategy for English-Czech and English-German translation scenarios, obtaining improvements in both settings. We furthermore show that the improvement is not due to only adding explicit morphological information.