 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Machine Learning Techniques to Identify Important Factors Leading to Injury in Curve Related Crashes
Jan 04, 2023Different factors have effects on traffic crashes and crash-related injuries. These factors include segment characteristics, crash-level characteristics, occupant level characteristics, environment characteristics, and vehicle level characteristics. There are several studies regarding these factors' effects on crash injuries. However, limited studies have examined the effects of pre-crash events on injuries, especially for curve-related crashes. The majority of previous studies for curve-related crashes focused on the impact of geometric features or street design factors. The current study tries to eliminate the aforementioned shortcomings by considering important pre-crash events related factors as selected variables and the number of vehicles with or without injury as the predicted variable. This research used CRSS data from the National Highway Traffic Safety Administration (NHTSA), which includes traffic crash-related data for different states in the USA. The relationships are explored using different machine learning algorithms like the random forest, C5.0, CHAID, Bayesian Network, Neural Network, C\&R Tree, Quest, etc. The random forest and SHAP values are used to identify the most effective variables. The C5.0 algorithm, which has the highest accuracy rate among the other algorithms, is used to develop the final model. Analysis results revealed that the extent of the damage, critical pre-crash event, pre-impact location, the trafficway description, roadway surface condition, the month of the crash, the first harmful event, number of motor vehicles, attempted avoidance maneuver, and roadway grade affect the number of vehicles with or without injury in curve-related crashes.
An investigation into machine learning approaches for forecasting spatio-temporal demand in ride-hailing service
Mar 07, 2017


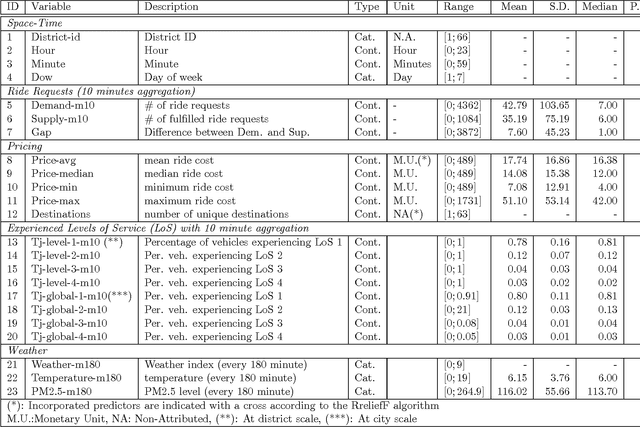
In this paper, we present machine learning approaches for characterizing and forecasting the short-term demand for on-demand ride-hailing services. We propose the spatio-temporal estimation of the demand that is a function of variable effects related to traffic, pricing and weather conditions. With respect to the methodology, a single decision tree, bootstrap-aggregated (bagged) decision trees, random forest, boosted decision trees, and artificial neural network for regression have been adapted and systematically compared using various statistics, e.g. R-square, Root Mean Square Error (RMSE), and slope. To better assess the quality of the models, they have been tested on a real case study using the data of DiDi Chuxing, the main on-demand ride hailing service provider in China. In the current study, 199,584 time-slots describing the spatio-temporal ride-hailing demand has been extracted with an aggregated-time interval of 10 mins. All the methods are trained and validated on the basis of two independent samples from this dataset. The results revealed that boosted decision trees provide the best prediction accuracy (RMSE=16.41), while avoiding the risk of over-fitting, followed by artificial neural network (20.09), random forest (23.50), bagged decision trees (24.29) and single decision tree (33.55).