 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering individual emotional states from sparse ratings using collaborative filtering
Sep 14, 2021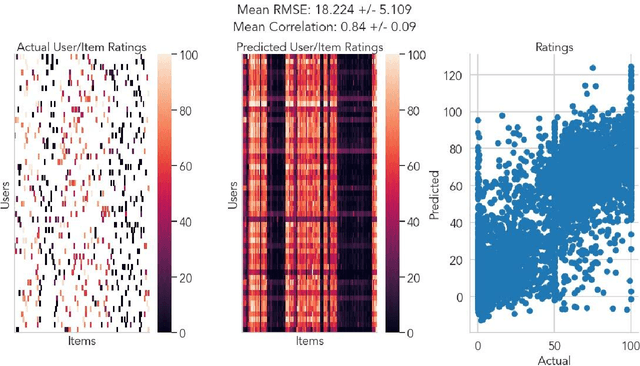
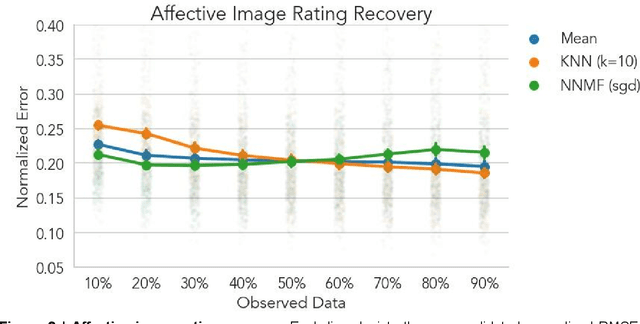
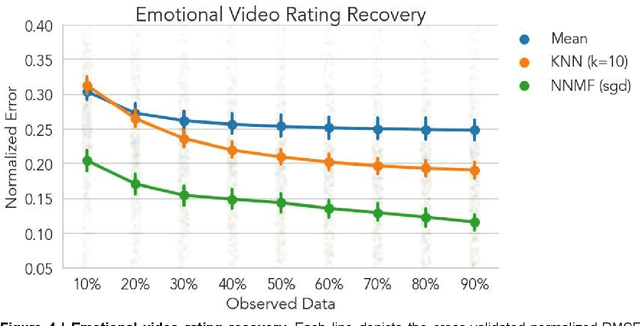

A fundamental challenge in emotion research is measuring feeling states with high granularity and temporal precision without disrupting the emotion generation process. Here we introduce and validate a new approach in which responses are sparsely sampled and the missing data are recovered using a computational technique known as collaborative filtering (CF). This approach leverages structured covariation across individual experiences and is available in Neighbors, an open-source Python toolbox. We validate our approach across three different experimental contexts by recovering dense individual ratings using only a small subset of the original data. In dataset 1, participants (n=316) separately rated 112 emotional images on 6 different discrete emotions. In dataset 2, participants (n=203) watched 8 short emotionally engaging autobiographical stories while simultaneously providing moment-by-moment ratings of the intensity of their affective experience. In dataset 3, participants (n=60) with distinct social preferences made 76 decisions about how much money to return in a hidden multiplier trust game. Across all experimental contexts, CF was able to accurately recover missing data and importantly outperformed mean imputation, particularly in contexts with greater individual variability. This approach will enable new avenues for affective science research by allowing researchers to acquire high dimensional ratings from emotional experiences with minimal disruption to the emotion-generation process.
Modeling emotion in complex stories: the Stanford Emotional Narratives Dataset
Nov 22, 2019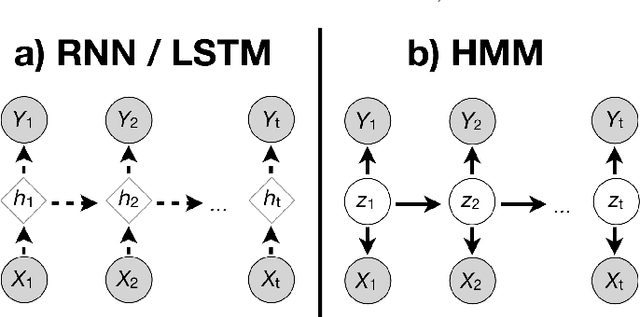
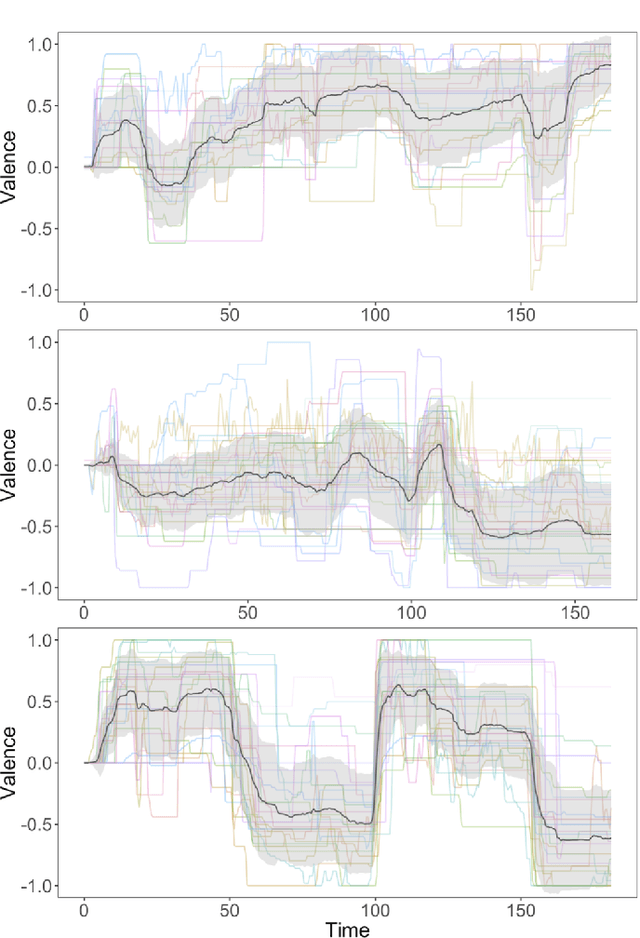
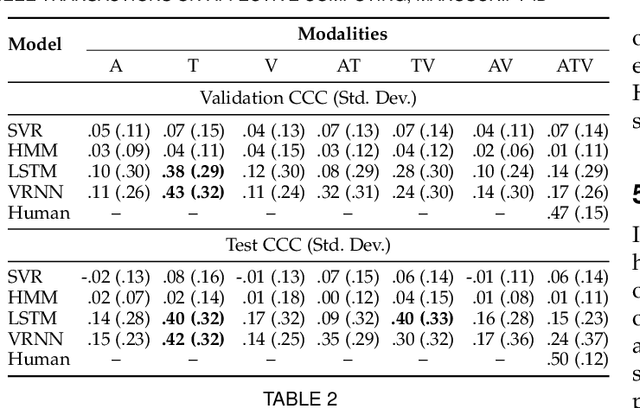
Human emotions unfold over time, and more affective computing research has to prioritize capturing this crucial component of real-world affect. Modeling dynamic emotional stimuli requires solving the twin challenges of time-series modeling and of collecting high-quality time-series datasets. We begin by assessing the state-of-the-art in time-series emotion recognition, and we review contemporary time-series approaches in affective computing, including discriminative and generative models. We then introduce the first version of the Stanford Emotional Narratives Dataset (SENDv1): a set of rich, multimodal videos of self-paced, unscripted emotional narratives, annotated for emotional valence over time. The complex narratives and naturalistic expressions in this dataset provide a challenging test for contemporary time-series emotion recognition models. We demonstrate several baseline and state-of-the-art modeling approaches on the SEND, including a Long Short-Term Memory model and a multimodal Variational Recurrent Neural Network, which perform comparably to the human-benchmark. We end by discussing the implications for future research in time-series affective computing.