 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeanReasoner: Boosting Complex Logical Reasoning with Lean
Mar 20, 2024Large language models (LLMs) often struggle with complex logical reasoning due to logical inconsistencies and the inherent difficulty of such reasoning. We use Lean, a theorem proving framework, to address these challenges. By formalizing logical reasoning problems into theorems within Lean, we can solve them by proving or disproving the corresponding theorems. This method reduces the risk of logical inconsistencies with the help of Lean's symbolic solver. It also enhances our ability to treat complex reasoning tasks by using Lean's extensive library of theorem proofs. Our method achieves state-of-the-art performance on the FOLIO dataset and achieves performance near this level on ProofWriter. Notably, these results were accomplished by fine-tuning on fewer than 100 in-domain samples for each dataset.
Can Large Language Model Summarizers Adapt to Diverse Scientific Communication Goals?
Jan 18, 2024In this work, we investigate the controllability of large language models (LLMs) on scientific summarization tasks. We identify key stylistic and content coverage factors that characterize different types of summaries such as paper reviews, abstracts, and lay summaries. By controlling stylistic features, we find that non-fine-tuned LLMs outperform humans in the MuP review generation task, both in terms of similarity to reference summaries and human preferences. Also, we show that we can improve the controllability of LLMs with keyword-based classifier-free guidance (CFG) while achieving lexical overlap comparable to strong fine-tuned baselines on arXiv and PubMed. However, our results also indicate that LLMs cannot consistently generate long summaries with more than 8 sentences. Furthermore, these models exhibit limited capacity to produce highly abstractive lay summaries. Although LLMs demonstrate strong generic summarization competency, sophisticated content control without costly fine-tuning remains an open problem for domain-specific applications.
Can Large Language Models Follow Concept Annotation Guidelines? A Case Study on Scientific and Financial Domains
Nov 15, 2023



Although large language models (LLMs) exhibit remarkable capacity to leverage in-context demonstrations, it is still unclear to what extent they can learn new concepts or facts from ground-truth labels. To address this question, we examine the capacity of instruction-tuned LLMs to follow in-context concept guidelines for sentence labeling tasks. We design guidelines that present different types of factual and counterfactual concept definitions, which are used as prompts for zero-shot sentence classification tasks. Our results show that although concept definitions consistently help in task performance, only the larger models (with 70B parameters or more) have limited ability to work under counterfactual contexts. Importantly, only proprietary models such as GPT-3.5 and GPT-4 can recognize nonsensical guidelines, which we hypothesize is due to more sophisticated alignment methods. Finally, we find that Falcon-180B-chat is outperformed by Llama-2-70B-chat is most cases, which indicates that careful fine-tuning is more effective than increasing model scale. Altogether, our simple evaluation method reveals significant gaps in concept understanding between the most capable open-source language models and the leading proprietary APIs.
Factorizing Content and Budget Decisions in Abstractive Summarization of Long Documents by Sampling Summary Views
May 25, 2022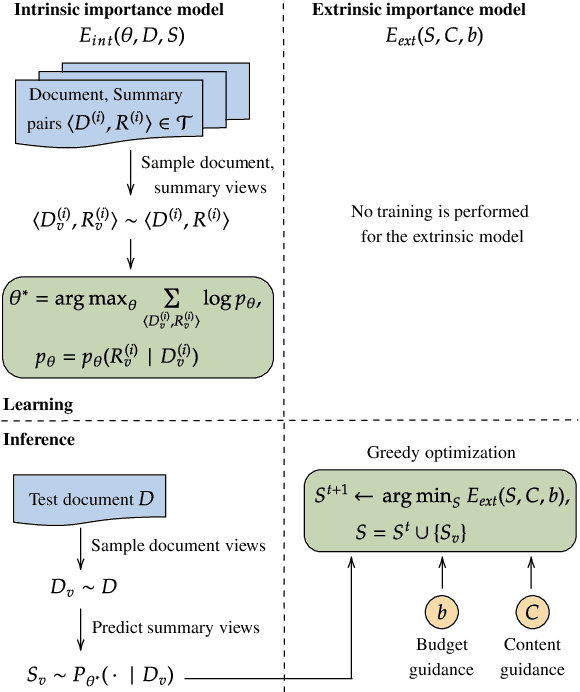

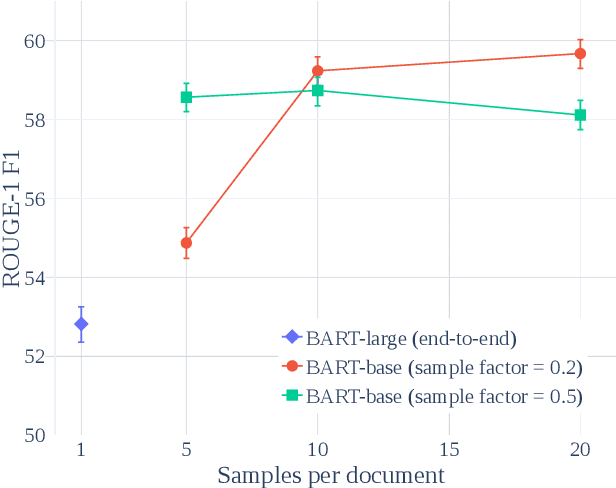
We argue that disentangling content selection from the budget used to cover salient content improves the performance and applicability of abstractive summarizers. Our method, FactorSum, does this disentanglement by factorizing summarization into two steps through an energy function: (1) generation of abstractive summary views; (2) combination of these views into a final summary, following a budget and content guidance. This guidance may come from different sources, including from an advisor model such as BART or BigBird, or in oracle mode -- from the reference. This factorization achieves significantly higher ROUGE scores on multiple benchmarks for long document summarization, namely PubMed, arXiv, and GovReport. Most notably, our model is effective for domain adaptation. When trained only on PubMed samples, it achieves a 46.29 ROUGE-1 score on arXiv, which indicates a strong performance due to more flexible budget adaptation and content selection less dependent on domain-specific textual structure.
Unsupervised predictive coding models may explain visual brain representation
Jun 30, 2019


Deep predictive coding networks are neuroscience-inspired unsupervised learning models that learn to predict future sensory states. We build upon the PredNet implementation by Lotter, Kreiman, and Cox (2016) to investigate if predictive coding representations are useful to predict brain activity in the visual cortex. We use representational similarity analysis (RSA) to compare PredNet representations to functional magnetic resonance imaging (fMRI) and magnetoencephalography (MEG) data from the Algonauts Project. In contrast to previous findings in the literature (Khaligh-Razavi &Kriegeskorte, 2014), we report empirical data suggesting that unsupervised models trained to predict frames of videos may outperform supervised image classification baselines. Our best submission achieves an average noise normalized score of 16.67% and 27.67% on the fMRI and MEG tracks of the Algonauts Challenge.