 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of lead position, cardiac rhythm variation and drug-induced QT prolongation on performance of machine learning methods for ECG processing
Dec 10, 2019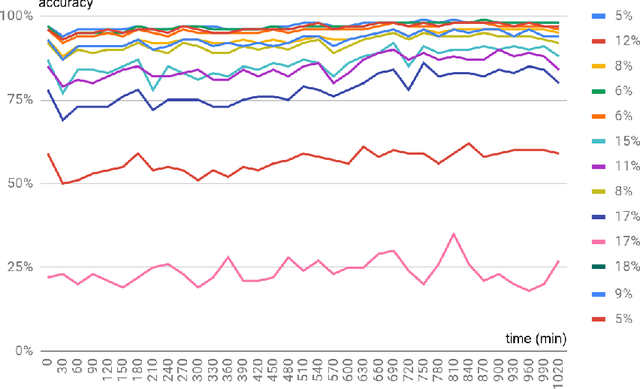
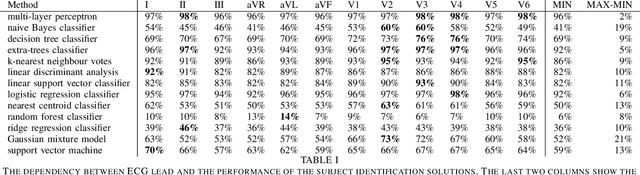
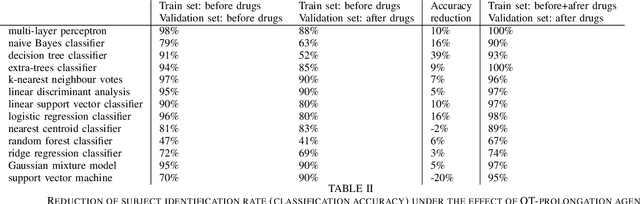
Machine learning shows great performance in various problems of electrocardiography (ECG) signal analysis. However, collecting of any dataset for biomedical engineering is a very difficult task. Any datasets for ECG processing contains from 100 to 10,000 times fewer cases than datasets for image or text analysis. This issue is especially important because of physiological phenomena that can significantly change the morphology of heartbeats in ECG signals. In this preliminary study, we analyze the effects of lead choice from the standard ECG recordings, a variation of ECG during 24-hours, and the effects of QT-prolongation agents on the performance of machine learning methods for ECG processing. We choose the problem of subject identification for analysis, because this problem may be solved for almost any available dataset of ECG data. In a discussion, we compare our findings with observations from other works that use machine learning for ECG processing with different problem statements. Our results show the importance of training dataset enrichment with ECG signals that acquired in specific physiological conditions for obtaining good performance of ECG processing for real applications.