 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReleasing Differentially Private Event Logs Using Generative Models
Apr 08, 2025In recent years, the industry has been witnessing an extended usage of process mining and automated event data analysis. Consequently, there is a rising significance in addressing privacy apprehensions related to the inclusion of sensitive and private information within event data utilized by process mining algorithms. State-of-the-art research mainly focuses on providing quantifiable privacy guarantees, e.g., via differential privacy, for trace variants that are used by the main process mining techniques, e.g., process discovery. However, privacy preservation techniques designed for the release of trace variants are still insufficient to meet all the demands of industry-scale utilization. Moreover, ensuring privacy guarantees in situations characterized by a high occurrence of infrequent trace variants remains a challenging endeavor. In this paper, we introduce two novel approaches for releasing differentially private trace variants based on trained generative models. With TraVaG, we leverage \textit{Generative Adversarial Networks} (GANs) to sample from a privatized implicit variant distribution. Our second method employs \textit{Denoising Diffusion Probabilistic Models} that reconstruct artificial trace variants from noise via trained Markov chains. Both methods offer industry-scale benefits and elevate the degree of privacy assurances, particularly in scenarios featuring a substantial prevalence of infrequent variants. Also, they overcome the shortcomings of conventional privacy preservation techniques, such as bounding the length of variants and introducing fake variants. Experimental results on real-life event data demonstrate that our approaches surpass state-of-the-art techniques in terms of privacy guarantees and utility preservation.
Extracting Rules from Event Data for Study Planning
Oct 04, 2023In this study, we examine how event data from campus management systems can be used to analyze the study paths of higher education students. The main goal is to offer valuable guidance for their study planning. We employ process and data mining techniques to explore the impact of sequences of taken courses on academic success. Through the use of decision tree models, we generate data-driven recommendations in the form of rules for study planning and compare them to the recommended study plan. The evaluation focuses on RWTH Aachen University computer science bachelor program students and demonstrates that the proposed course sequence features effectively explain academic performance measures. Furthermore, the findings suggest avenues for developing more adaptable study plans.
TraVaG: Differentially Private Trace Variant Generation Using GANs
Mar 29, 2023Process mining is rapidly growing in the industry. Consequently, privacy concerns regarding sensitive and private information included in event data, used by process mining algorithms, are becoming increasingly relevant. State-of-the-art research mainly focuses on providing privacy guarantees, e.g., differential privacy, for trace variants that are used by the main process mining techniques, e.g., process discovery. However, privacy preservation techniques for releasing trace variants still do not fulfill all the requirements of industry-scale usage. Moreover, providing privacy guarantees when there exists a high rate of infrequent trace variants is still a challenge. In this paper, we introduce TraVaG as a new approach for releasing differentially private trace variants based on \text{Generative Adversarial Networks} (GANs) that provides industry-scale benefits and enhances the level of privacy guarantees when there exists a high ratio of infrequent variants. Moreover, TraVaG overcomes shortcomings of conventional privacy preservation techniques such as bounding the length of variants and introducing fake variants. Experimental results on real-life event data show that our approach outperforms state-of-the-art techniques in terms of privacy guarantees, plain data utility preservation, and result utility preservation.
Trustworthy Artificial Intelligence and Process Mining: Challenges and Opportunities
Oct 06, 2021
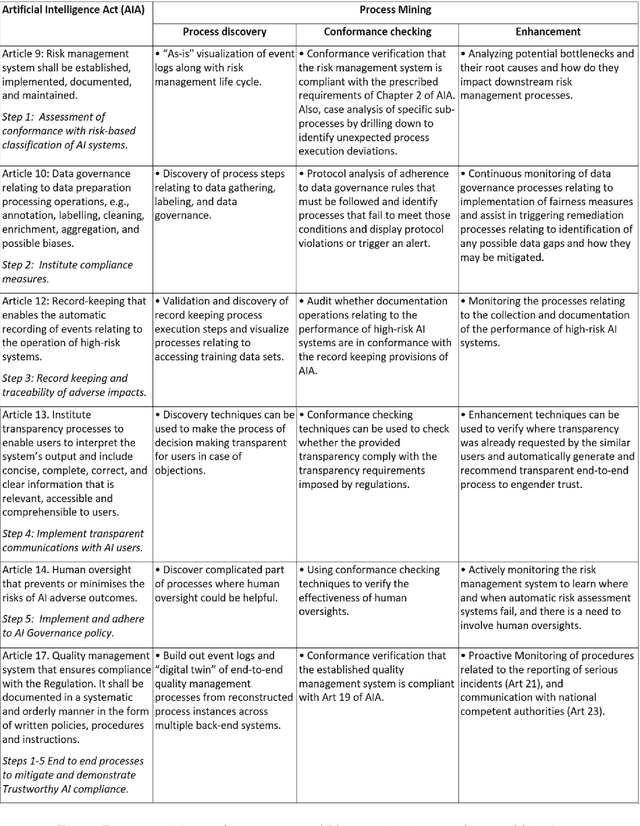
The premise of this paper is that compliance with Trustworthy AI governance best practices and regulatory frameworks is an inherently fragmented process spanning across diverse organizational units, external stakeholders, and systems of record, resulting in process uncertainties and in compliance gaps that may expose organizations to reputational and regulatory risks. Moreover, there are complexities associated with meeting the specific dimensions of Trustworthy AI best practices such as data governance, conformance testing, quality assurance of AI model behaviors, transparency, accountability, and confidentiality requirements. These processes involve multiple steps, hand-offs, re-works, and human-in-the-loop oversight. In this paper, we demonstrate that process mining can provide a useful framework for gaining fact-based visibility to AI compliance process execution, surfacing compliance bottlenecks, and providing for an automated approach to analyze, remediate and monitor uncertainty in AI regulatory compliance processes.