 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentral Description Length (CDL) Clustering Validation Index
Jun 02, 2026Selecting a clustering algorithm and its hyperparameters without labels is a common difficulty in engineering machine learning pipelines that work with unsupervised analysis of sensor, image, or process data. Clustering validation indices (CVIs) provide internal scores for ranking candidate clusterings, but most popular CVIs are built from Euclidean compactness and separation terms and so tend to favour compact, convex partitions. Their performance is known to degrade on non convex, irregular, or variable density data, where kernel transformations or alternative distance measures are typically used at the cost of additional tuning and computation. This paper introduces the Central Description Length (CDL) clustering validation index. CDL uses the observed within cluster compactness, the estimated cluster centers, and the estimated cluster covariances to compute a probabilistic upper bound on the description length associated with the unobservable true cluster centers. The bound condenses intra cluster compactness and centroid displacement into a single computable quantity and is evaluated on the partition produced by any clustering algorithm. The implementation uses only observable quantities (the data, the partition, the estimated centers, and the estimated covariances) and does not use ground truth labels. On synthetic benchmarks with non convex and arbitrary shape clusters, CDL-CVI selected the reference number of clusters more often and reached higher Adjusted Rand Index (ARI) values than the conventional CVIs we tested, without an additional kernel preprocessing stage. On image benchmarks (MNIST, CIFAR-10, STL-10) clustered from frozen unsupervised embeddings, CDL-CVI returned cluster numbers close to the reference class counts across K-means, DBSCAN, and spectral clustering in the reported trials.
Secure Blind Graph Signal Recovery and Adversary Detection Using Smoothness Maximization
Sep 17, 2025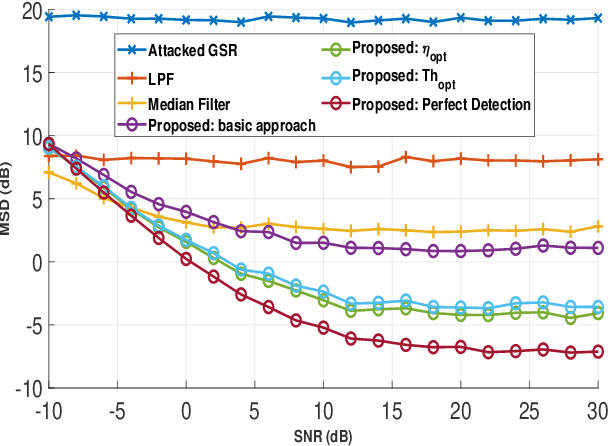
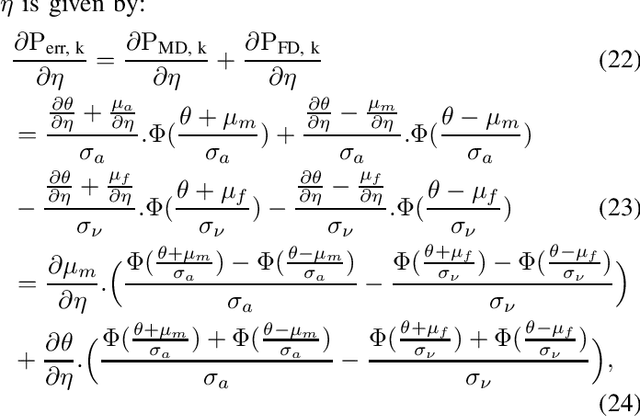
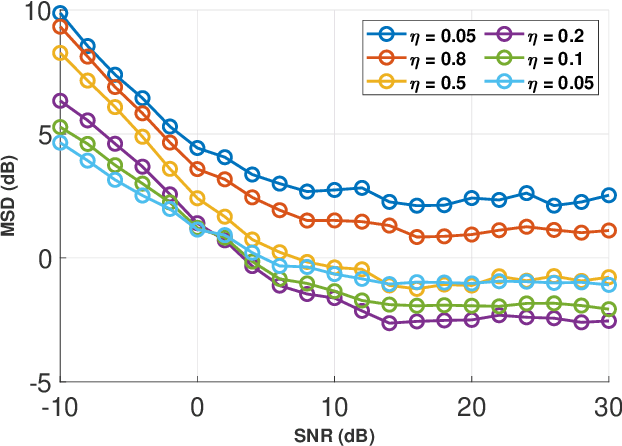
In this letter, we propose a secure blind Graph Signal Recovery (GSR) algorithm that can detect adversary nodes. Some unknown adversaries are assumed to be injecting false data at their respective nodes in the graph. The number and location of adversaries are not known in advance and the goal is to recover the graph signal in the presence of measurement noise and False Data Injection (FDI) caused by the adversaries. Consequently, the proposed algorithm would be a perfect candidate to solve this challenging problem. Moreover, due to the presence of malicious nodes, the proposed method serves as a secure GSR algorithm. For adversary detection, a statistical measure based on differential smoothness is used. Specifically, the difference between the current observed smoothness and the average smoothness excluding the corresponding node. This genuine statistical approach leads to an effective and low-complexity adversary detector. In addition, following malicious node detection, the GSR is performed using a variant of smoothness maximization, which is solved efficiently as a fractional optimization problem using a Dinkelbach's algorithm. Analysis of the detector, which determines the optimum threshold of the detector is also presented. Simulation results show a significant improvement of the proposed method in signal recovery compared to the median GSR algorithm and other competing methods.
Distributed Estimation with Partially Accessible Information: An IMAT Approach to LMS Diffusion
Oct 17, 2023

Distributed algorithms, particularly Diffusion Least Mean Square, are widely favored for their reliability, robustness, and fast convergence in various industries. However, limited observability of the target can compromise the integrity of the algorithm. To address this issue, this paper proposes a framework for analyzing combination strategies by drawing inspiration from signal flow analysis. A thresholding-based algorithm is also presented to identify and utilize the support vector in scenarios with missing information about the target vector's support. The proposed approach is demonstrated in two combination scenarios, showcasing the effectiveness of the algorithm in situations characterized by sparse observations in the time and transform domains.
Enhancing the SEFDM Performance in High-Doppler Channels
Sep 21, 2023In this paper, we propose the use of Spectrally Efficient Frequency Division Multiplexing (SEFDM) with additional techniques such as Frequency Domain Cyclic Prefix (FDCP) and Modified Non-Linear (MNL) acceleration for efficient handling of the impact of delay and Doppler shift in mobile communication channels. Our approach exhibits superior performance and spectral efficiency in comparison to traditional communication systems, while maintaining low computational cost. We study a model of the SEFDM communication system and investigate the impact of MNL acceleration with soft and hard decision Inverse System on the performance of SEFDM detection in the AWGN channel. We also analyze the effectiveness of FDCP in compensating for the impact of Doppler shift, and report BER detection figures using Regularized Sphere Decoding in various simulation scenarios. Our simulations demonstrate that it is possible to achieve acceptable performance in Doppler channels while maintaining the superiority of SEFDM over OFDM in terms of spectral efficiency. The results suggest that our proposed approach can tackle the effects of delay and Doppler shift in mobile communication networks, guaranteeing dependable and high-quality communication even in extremely challenging environments.
Non-Orthogonal Time-Frequency Space Modulation
Sep 21, 2023



This paper proposes a Time-Frequency Space Transformation (TFST) to derive non-orthogonal bases for modulation techniques over the delay-doppler plane. A family of Overloaded Delay-Doppler Modulation (ODDM) techniques is proposed based on the TFST, which enhances flexibility and efficiency by expressing modulated signals as a linear combination of basis signals. A Non-Orthogonal Time-Frequency Space (NOTFS) digital modulation is derived for the proposed ODDM techniques, and simulations show that they offer high-mobility communication systems with improved spectral efficiency and low latency, particularly in challenging scenarios such as high overloading factors and Additive White Gaussian Noise (AWGN) channels. A modified sphere decoding algorithm is also presented to efficiently decode the received signal. The proposed modulation and decoding techniques contribute to the advancement of non-orthogonal approaches in the next-generation of mobile communication systems, delivering superior spectral efficiency and low latency, and offering a promising solution towards the development of efficient high-mobility communication systems.
Separability and Scatteredness (S&S) Ratio-Based Efficient SVM Regularization Parameter, Kernel, and Kernel Parameter Selection
May 17, 2023Support Vector Machine (SVM) is a robust machine learning algorithm with broad applications in classification, regression, and outlier detection. SVM requires tuning the regularization parameter (RP) which controls the model capacity and the generalization performance. Conventionally, the optimum RP is found by comparison of a range of values through the Cross-Validation (CV) procedure. In addition, for non-linearly separable data, the SVM uses kernels where a set of kernels, each with a set of parameters, denoted as a grid of kernels, are considered. The optimal choice of RP and the grid of kernels is through the grid-search of CV. By stochastically analyzing the behavior of the regularization parameter, this work shows that the SVM performance can be modeled as a function of separability and scatteredness (S&S) of the data. Separability is a measure of the distance between classes, and scatteredness is the ratio of the spread of data points. In particular, for the hinge loss cost function, an S&S ratio-based table provides the optimum RP. The S&S ratio is a powerful value that can automatically detect linear or non-linear separability before using the SVM algorithm. The provided S&S ratio-based table can also provide the optimum kernel and its parameters before using the SVM algorithm. Consequently, the computational complexity of the CV grid-search is reduced to only one time use of the SVM. The simulation results on the real dataset confirm the superiority and efficiency of the proposed approach in the sense of computational complexity over the grid-search CV method.
Learnability, Sample Complexity, and Hypothesis Class Complexity for Regression Models
Mar 28, 2023The goal of a learning algorithm is to receive a training data set as input and provide a hypothesis that can generalize to all possible data points from a domain set. The hypothesis is chosen from hypothesis classes with potentially different complexities. Linear regression modeling is an important category of learning algorithms. The practical uncertainty of the target samples affects the generalization performance of the learned model. Failing to choose a proper model or hypothesis class can lead to serious issues such as underfitting or overfitting. These issues have been addressed by alternating cost functions or by utilizing cross-validation methods. These approaches can introduce new hyperparameters with their own new challenges and uncertainties or increase the computational complexity of the learning algorithm. On the other hand, the theory of probably approximately correct (PAC) aims at defining learnability based on probabilistic settings. Despite its theoretical value, PAC does not address practical learning issues on many occasions. This work is inspired by the foundation of PAC and is motivated by the existing regression learning issues. The proposed approach, denoted by epsilon-Confidence Approximately Correct (epsilon CoAC), utilizes Kullback Leibler divergence (relative entropy) and proposes a new related typical set in the set of hyperparameters to tackle the learnability issue. Moreover, it enables the learner to compare hypothesis classes of different complexity orders and choose among them the optimum with the minimum epsilon in the epsilon CoAC framework. Not only the epsilon CoAC learnability overcomes the issues of overfitting and underfitting, but it also shows advantages and superiority over the well known cross-validation method in the sense of time consumption as well as in the sense of accuracy.
Algorithmic Trading Using Continuous Action Space Deep Reinforcement Learning
Oct 07, 2022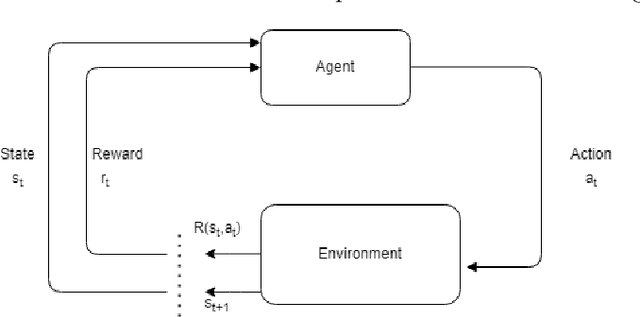



Price movement prediction has always been one of the traders' concerns in financial market trading. In order to increase their profit, they can analyze the historical data and predict the price movement. The large size of the data and complex relations between them lead us to use algorithmic trading and artificial intelligence. This paper aims to offer an approach using Twin-Delayed DDPG (TD3) and the daily close price in order to achieve a trading strategy in the stock and cryptocurrency markets. Unlike previous studies using a discrete action space reinforcement learning algorithm, the TD3 is continuous, offering both position and the number of trading shares. Both the stock (Amazon) and cryptocurrency (Bitcoin) markets are addressed in this research to evaluate the performance of the proposed algorithm. The achieved strategy using the TD3 is compared with some algorithms using technical analysis, reinforcement learning, stochastic, and deterministic strategies through two standard metrics, Return and Sharpe ratio. The results indicate that employing both position and the number of trading shares can improve the performance of a trading system based on the mentioned metrics.
Relative Entropy (RE) Based LTI System Modeling Equipped with time delay Estimation and Online Modeling
Oct 04, 2022
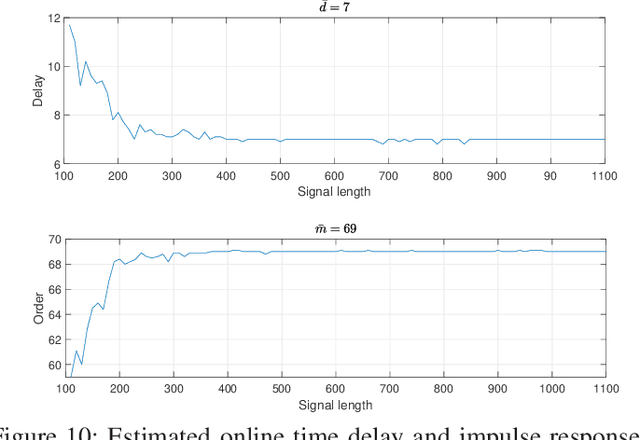


This paper proposes an impulse response modeling in presence of input and noisy output of a linear time-invariant (LTI) system. The approach utilizes Relative Entropy (RE) to choose the optimum impulse response estimate, optimum time delay and optimum impulse response length. The desired RE is the Kulback-Lielber divergence of the estimated distribution from its unknown true distribution. A unique probabilistic validation approach estimates the desired relative entropy and minimizes this criterion to provide the impulse response estimate. Classical methods have approached this system modeling problem from two separate angles for the time delay estimation and for the order selection. Time delay methods focus on time delay estimate minimizing various proposed criteria, while the existing order selection approaches choose the optimum impulse response length based on their proposed criteria. The strength of the proposed RE based method is in using the RE based criterion to estimate both the time delay and impulse response length simultaneously. In addition, estimation of the noise variance, when the Signal to Noise Ratio (SNR) is unknown is also concurrent and is based on optimizing the same RE based criterion. The RE based approach is also extended for online impulse response estimations. The online method reduces the model estimation computational complexity upon the arrival of a new sample. The introduced efficient stopping criteria for this online approaches is extremely valuable in practical applications. Simulation results illustrate precision and efficiency of the proposed method compared to the conventional time delay or order selection approaches.
Distributed interference cancellation in multi-agent scenarios
Oct 22, 2019
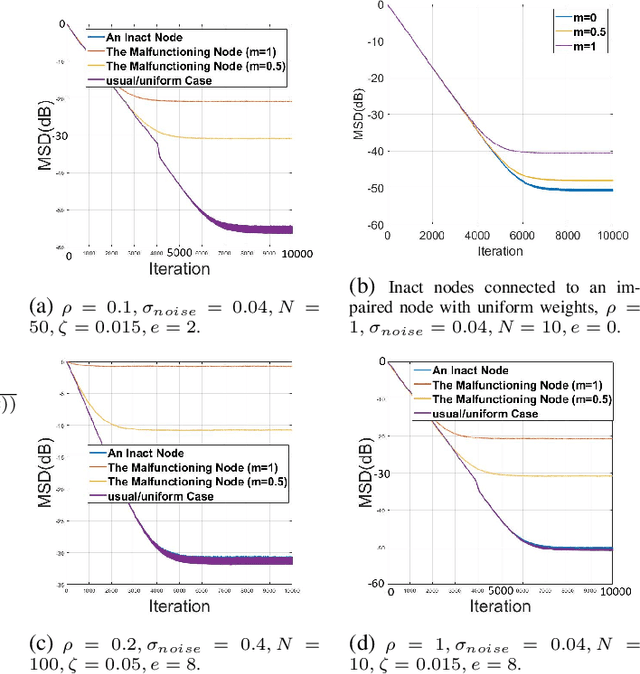
This paper considers the problem of detecting impaired and noisy nodes over network. In a distributed algorithm, lots of processing units are incorporating and communicating with each other to reach a global goal. Due to each one's state in the shared environment, they can help the other nodes or mislead them (due to noise or a deliberate attempt). Previous works mainly focused on proper locating agents and weight assignment based on initial environment state to minimize malfunctioning of noisy nodes. We propose an algorithm to be able to adapt sharing weights according to behavior of the agents. Applying the introduced algorithm to a multi-agent RL scenario and the well-known diffusion LMS demonstrates its capability and generality.