 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the use of adversarial validation for quantifying dissimilarity in geospatial machine learning prediction
Apr 19, 2024Recent geospatial machine learning studies have shown that the results of model evaluation via cross-validation (CV) are strongly affected by the dissimilarity between the sample data and the prediction locations. In this paper, we propose a method to quantify such a dissimilarity in the interval 0 to 100%, and from the perspective of the data feature space. The proposed method is based on adversarial validation, which is an approach that can check whether sample data and prediction locations can be separated with a binary classifier. To study the effectiveness and generality of our method, we tested it on a series of experiments based on both synthetic and real datasets and with gradually increasing dissimilarities. Results show that the proposed method can successfully quantify dissimilarity across the entire range of values. Next to this, we studied how dissimilarity affects CV evaluations by comparing the results of random CV and of two spatial CV methods, namely block and spatial+ CV. Our results showed that CV evaluations follow similar patterns in all datasets and predictions: when dissimilarity is low (usually lower than 30%), random CV provides the most accurate evaluation results. As dissimilarity increases, spatial CV methods, especially spatial+ CV, become more and more accurate and even outperforming random CV. When dissimilarity is high (>=90%), no CV method provides accurate evaluations. These results show the importance of considering feature space dissimilarity when working with geospatial machine learning predictions, and can help researchers and practitioners to select more suitable CV methods for evaluating their predictions.
Graph Regularized Nonnegative Matrix Factorization for Hyperspectral Data Unmixing
Nov 03, 2011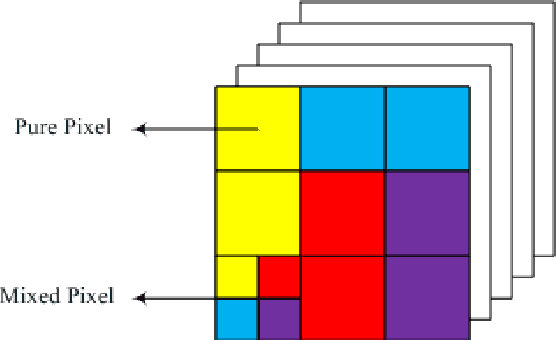


Spectral unmixing is an important tool in hyperspectral data analysis for estimating endmembers and abundance fractions in a mixed pixel. This paper examines the applicability of a recently developed algorithm called graph regularized nonnegative matrix factorization (GNMF) for this aim. The proposed approach exploits the intrinsic geometrical structure of the data besides considering positivity and full additivity constraints. Simulated data based on the measured spectral signatures, is used for evaluating the proposed algorithm. Results in terms of abundance angle distance (AAD) and spectral angle distance (SAD) show that this method can effectively unmix hyperspectral data.