 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReview of Zero-Shot and Few-Shot AI Algorithms in The Medical Domain
Jun 23, 2024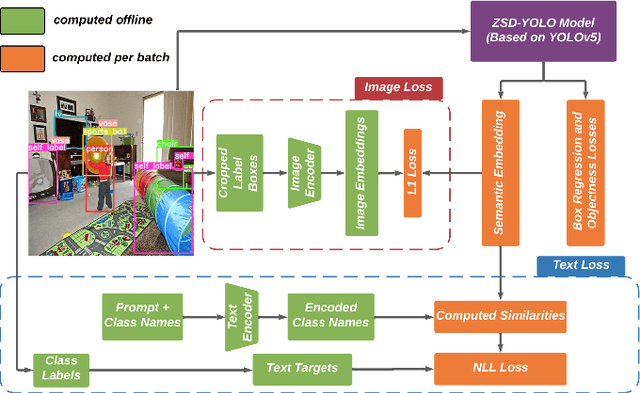
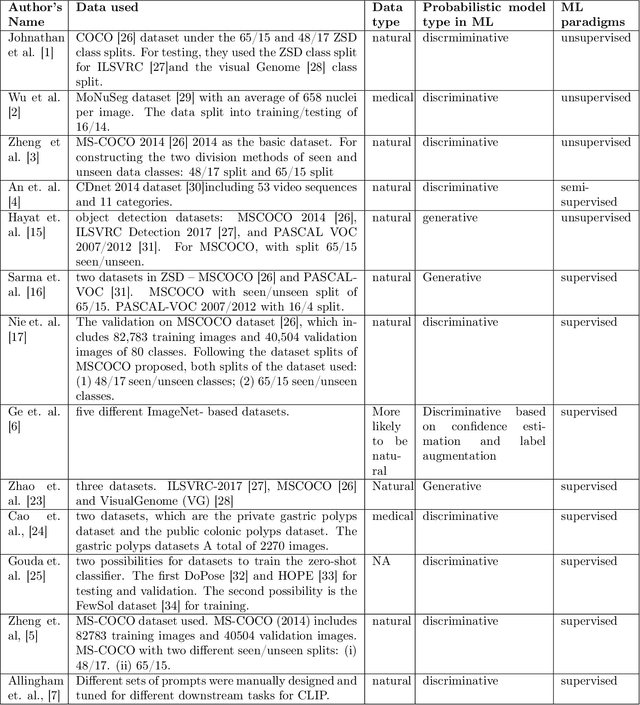
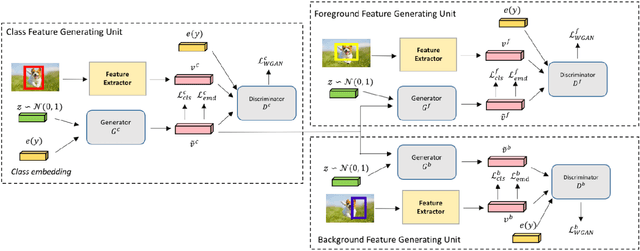
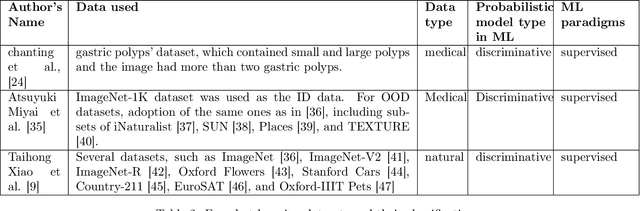
In this paper, different techniques of few-shot, zero-shot, and regular object detection have been investigated. The need for few-shot learning and zero-shot learning techniques is crucial and arises from the limitations and challenges in traditional machine learning, deep learning, and computer vision methods where they require large amounts of data, plus the poor generalization of those traditional methods. Those techniques can give us prominent results by using only a few training sets reducing the required amounts of data and improving the generalization. This survey will highlight the recent papers of the last three years that introduce the usage of few-shot learning and zero-shot learning techniques in addressing the challenges mentioned earlier. In this paper we reviewed the Zero-shot, few-shot and regular object detection methods and categorized them in an understandable manner. Based on the comparison made within each category. It been found that the approaches are quite impressive. This integrated review of diverse papers on few-shot, zero-shot, and regular object detection reveals a shared focus on advancing the field through novel frameworks and techniques. A noteworthy observation is the scarcity of detailed discussions regarding the difficulties encountered during the development phase. Contributions include the introduction of innovative models, such as ZSD-YOLO and GTNet, often showcasing improvements with various metrics such as mean average precision (mAP),Recall@100 (RE@100), the area under the receiver operating characteristic curve (AUROC) and precision. These findings underscore a collective move towards leveraging vision-language models for versatile applications, with potential areas for future research including a more thorough exploration of limitations and domain-specific adaptations.